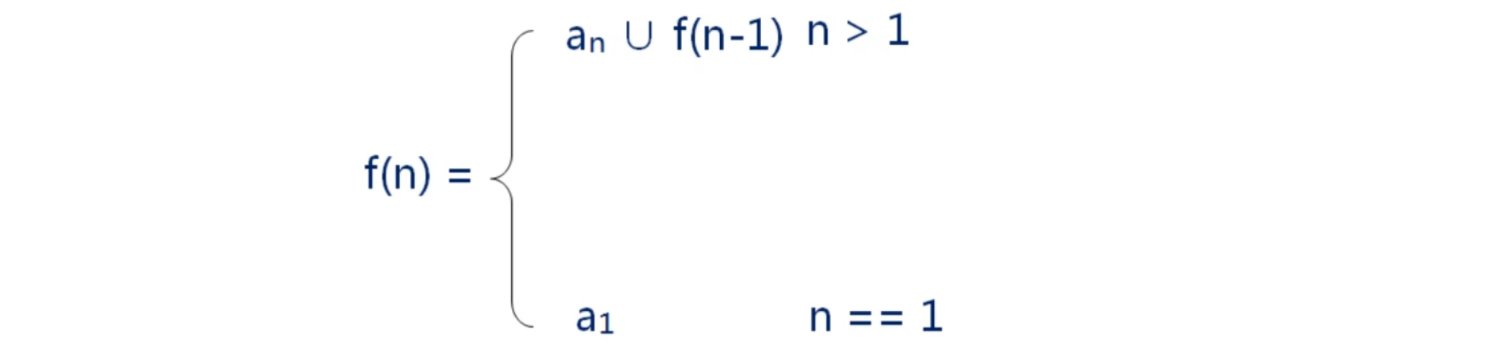什么是递归? – 递归是一种数学上分而自治的思想(问题分解)
– 递归与递推的思想相同,但是表现形式不同
递归在程序设计中的应用
递归与递推本质差异
思路:
先想代码出口,最简单的情况即一眼就能看出结果的情况(例如数组大小为1,树的节点只有1个等等)
再思考原问题如何分解小问题,找出递归式 ,注意小问题和原问题的状态应该是一样的
有时候可能有功能参数,比如记录路径,那么功能参数我们可以设为全局变量或者作为递归函数的引用参数
递归的划分子问题思想 查找一个无序数组的最大值空间复杂度O(log n)
初始思路:
1 2 3 4 5 int MaxInArray (int a[], int n) if (n == 1 )return a[0 ]; return std::max (MaxInArray (a, n - 1 ), a[n - 1 ]); }
非常的简单粗暴,但是这样的空间复杂度 是O(n)。函数调用栈过深,如果用二分的方式,函数两边的栈的深度差不多,但是总体栈深度大大降低,栈的深度变为了O(log n)
我们应该分而治之的思想,另外注意一般数组递归函数最好要有三个参数(数组自身,begin,end)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 int MaxInArray (int a[], int begin, int end) if (begin == end)return a[begin]; int mid = begin + ((end - begin) >> 1 ); int lmax = MaxInArray (a, begin, mid); int rmax = MaxInArray (a, mid + 1 , end); return lmax > rmax ? lmax : rmax; } int MaxInArray (int a[], int n) return MaxInArray (a, 0 , n - 1 ); }
二分子问题可以大大地减少栈深度
但是你以为这就完了吗?不,还有尾递归!
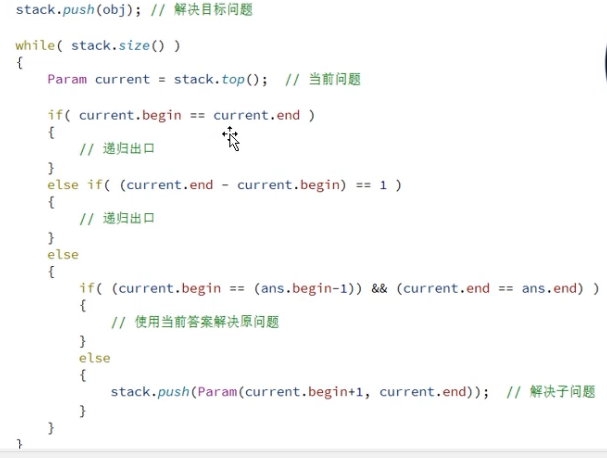
尾递归 递归改为循环 递归到非递归 • 核心:抓住递归的本质 , 使用栈数据结构模拟 递归调用
可使用栈数据结构模拟递归过程:
当前问题参数入栈 (递归调用)
参数出栈时,使用当前答案解决问题
标记当前问题已解决
注意 递归思想的非递归描述
只是模拟递归调用的过程
在代码结构上与递归实现几乎相同
框架:
求取集合的子集 尝试编写一个递归函数,用来输出 n 个元素的所有子集
这个题目表面上很简单,但并不是的!
删除无序链表重复节点 已知无序链表 L ,编写递归函数删除链表中的重复结点
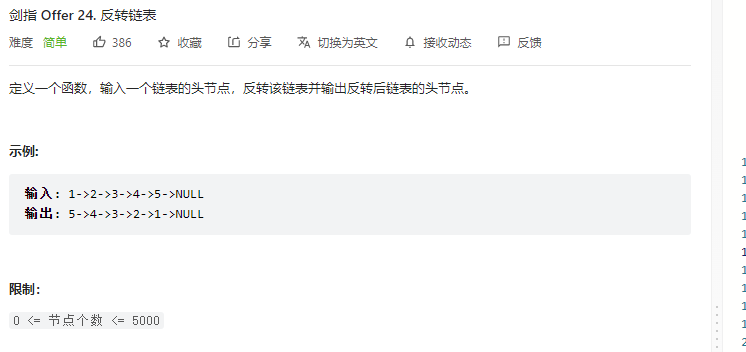
反转链表(简单)
1 2 3 4 5 6 7 8 9 ListNode* reverseList (ListNode* head) { if (!head || !head->next) { return head; } ListNode* newHead = reverseList (head->next); head->next->next = head; head->next = nullptr ; return newHead; }
二叉树和为某一值的路径
思维起点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {public : vector<vector<int >>res; vector<int >path; vector<vector<int >> pathSum (TreeNode* root, int target) { dfs (root,target); return res; } void dfs (TreeNode* root,int target) if (root == nullptr )return ; path.push_back (root->val); if (root->left==nullptr &&root->right==nullptr &&root->val == target){ res.push_back (path); } if (root->left!=nullptr )dfs (root->left,target-root->val); if (root->right!=nullptr )dfs (root->right,target-root->val); path.pop_back (); } };
特别注意:这一题要判断路径,我们因此必须将路径用容器存储。并且每次遍历了一个节点就将节点存入容器,遍历结束后就将节点pop出。
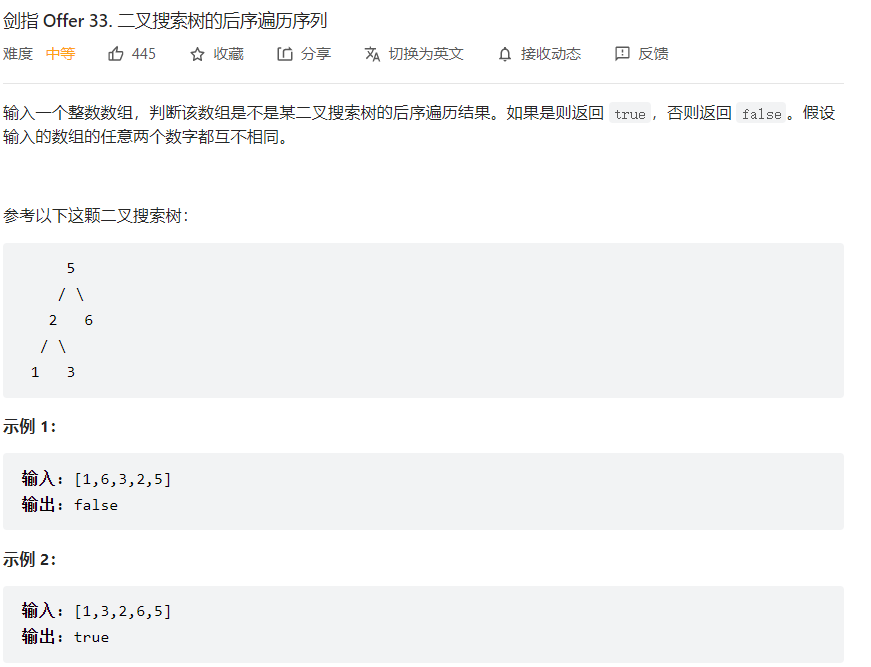
二叉搜索树的后序遍历序列
这个题的关键在于要先将左右子树划分好,划分完了在看左分区的大小是否小于根节点,右分区的大小是否都大于根节点。然后再对左右子树递归判断即可 。理清了二叉搜索树的判断那么代码就呼之欲出了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Solution {public : bool verifyPostorder (vector<int >& postorder) return verifyPostorder (postorder,0 ,postorder.size () - 1 ); } bool verifyPostorder (vector<int >& postorder,int begin,int end) if (end - begin <= 1 )return true ; int mid = begin; for (;(mid < end)&&(postorder[mid] < postorder[end]);mid++); for (int i = mid+1 ;i<end;i++) if (postorder[i] < postorder[end])return false ; return verifyPostorder (postorder,begin,mid-1 ) && verifyPostorder (postorder,mid,end-1 ); } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {private : unordered_map<int , int > index; public : TreeNode* myBuildTree (const vector<int >& preorder, const vector<int >& inorder, int preorder_left, int preorder_right, int inorder_left, int inorder_right) { if (preorder_left > preorder_right) { return nullptr ; } int preorder_root = preorder_left; int inorder_root = index[preorder[preorder_root]]; TreeNode* root = new TreeNode (preorder[preorder_root]); int size_left_subtree = inorder_root - inorder_left; root->left = myBuildTree (preorder, inorder, preorder_left + 1 , preorder_left + size_left_subtree, inorder_left, inorder_root - 1 ); root->right = myBuildTree (preorder, inorder, preorder_left + size_left_subtree + 1 , preorder_right, inorder_root + 1 , inorder_right); return root; } TreeNode* buildTree (vector<int >& preorder, vector<int >& inorder) { int n = preorder.size (); for (int i = 0 ; i < n; ++i) { index[inorder[i]] = i; } return myBuildTree (preorder, inorder, 0 , n - 1 , 0 , n - 1 ); } };
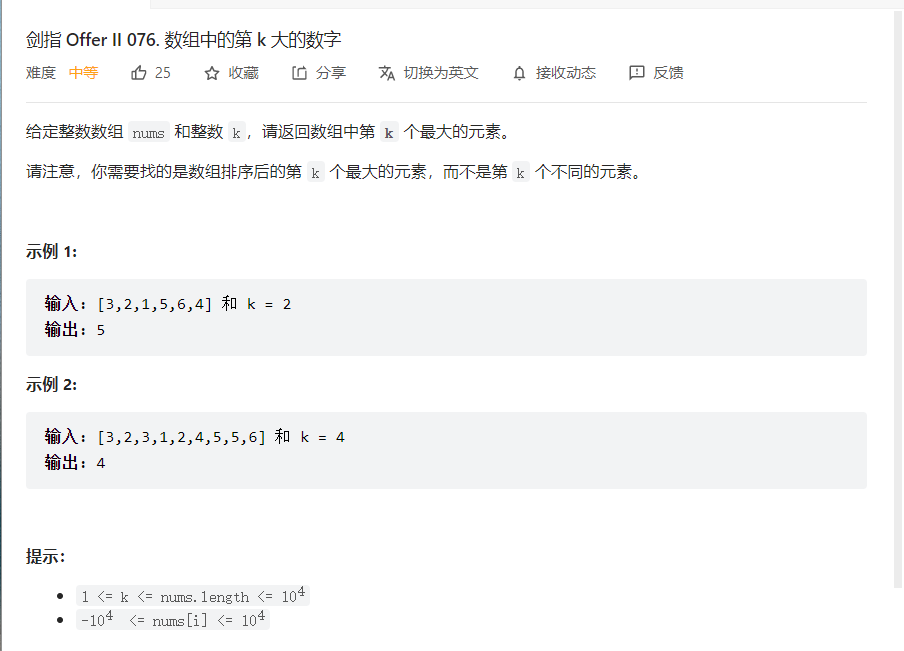
数组中第k大的数字(求取数组的中位数也是此解法)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class Solution {public : int partition (vector<int >& nums, int begin, int end) int pivot = nums[begin]; while (begin < end){ while (nums[end]<pivot&&begin < end)end--; nums[begin] = nums[end]; while (nums[begin]>=pivot&&begin < end)begin++; nums[end] = nums[begin]; } nums[begin] = pivot; return begin; } int findKthLargest (vector<int >& nums, int k, int begin, int end) if (begin == end)return nums[begin]; int ret = 0 ; int i = partition (nums, begin, end); if (i == k)ret = nums[i]; else if (i > k)ret = findKthLargest (nums, k,begin,i-1 ); else if (i < k)ret = findKthLargest (nums, k,i+1 ,end); return ret; } int findKthLargest (vector<int >& nums, int k) return findKthLargest (nums, k-1 , 0 , nums.size () - 1 ); } };