编译链接
编译模块
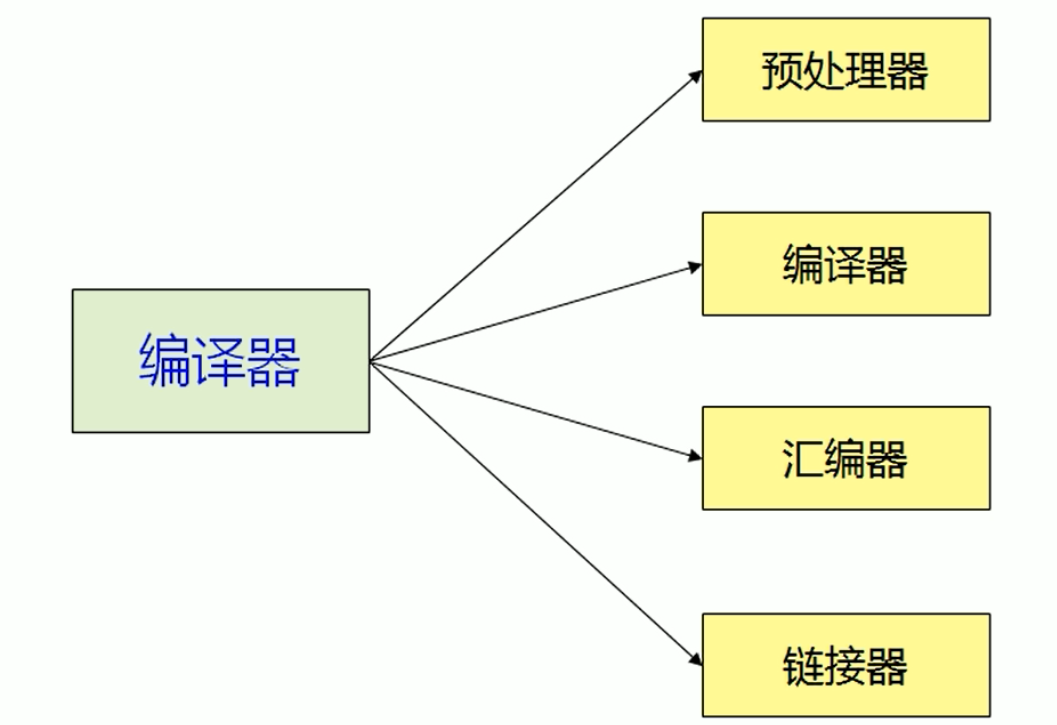
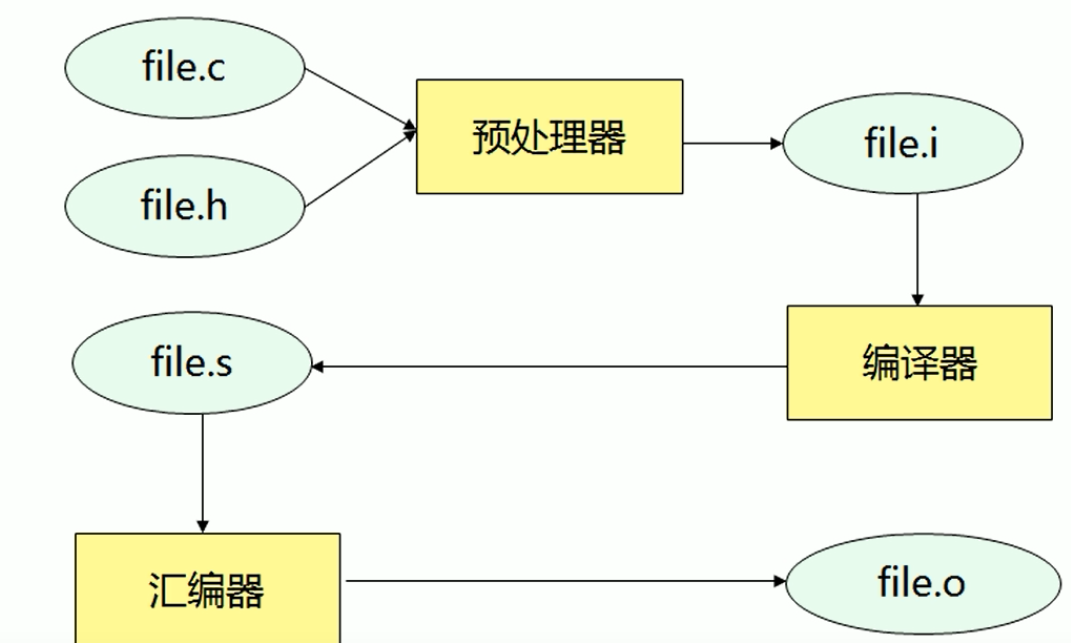
预编译
- 处理所有的注释,以空格代替
- 将所有的#define删除,并且展开所有的宏定义
- 处理条件编译指令#if, #ifdef, #elif, #else, #endif
- 处理#include ,展开被包含的文件
- 保留编译器需要使用的#pragma指令
预处理指令示例: gcc-E file.c -o file.i
范例
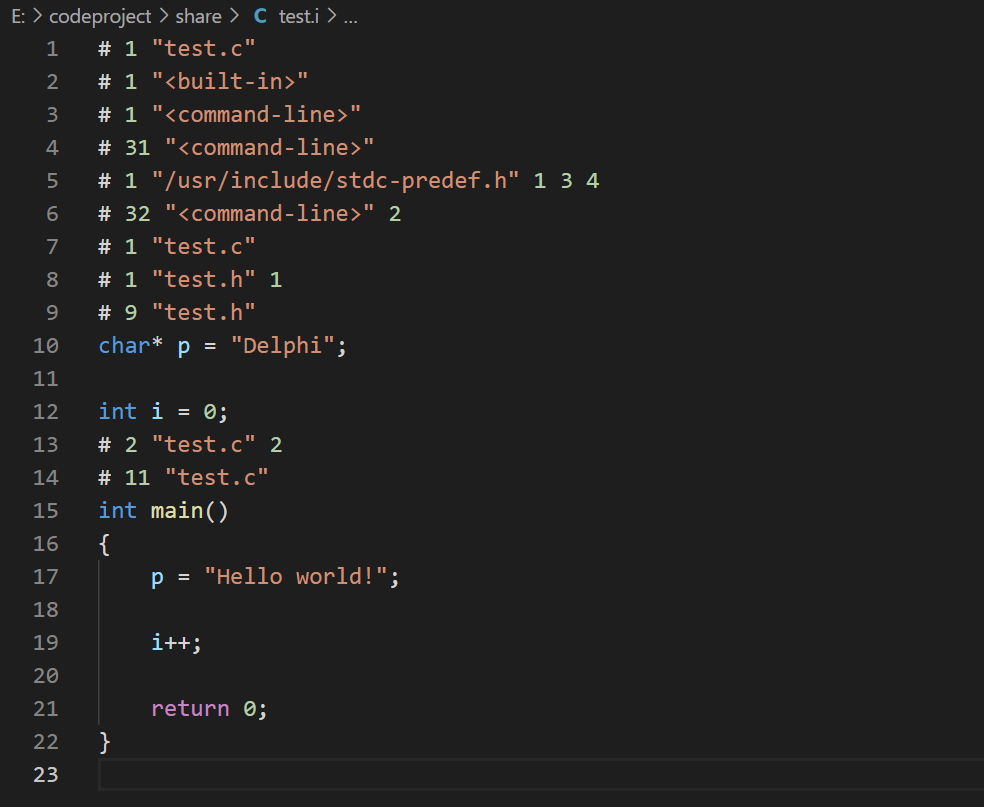
test.c与test.h如图所示
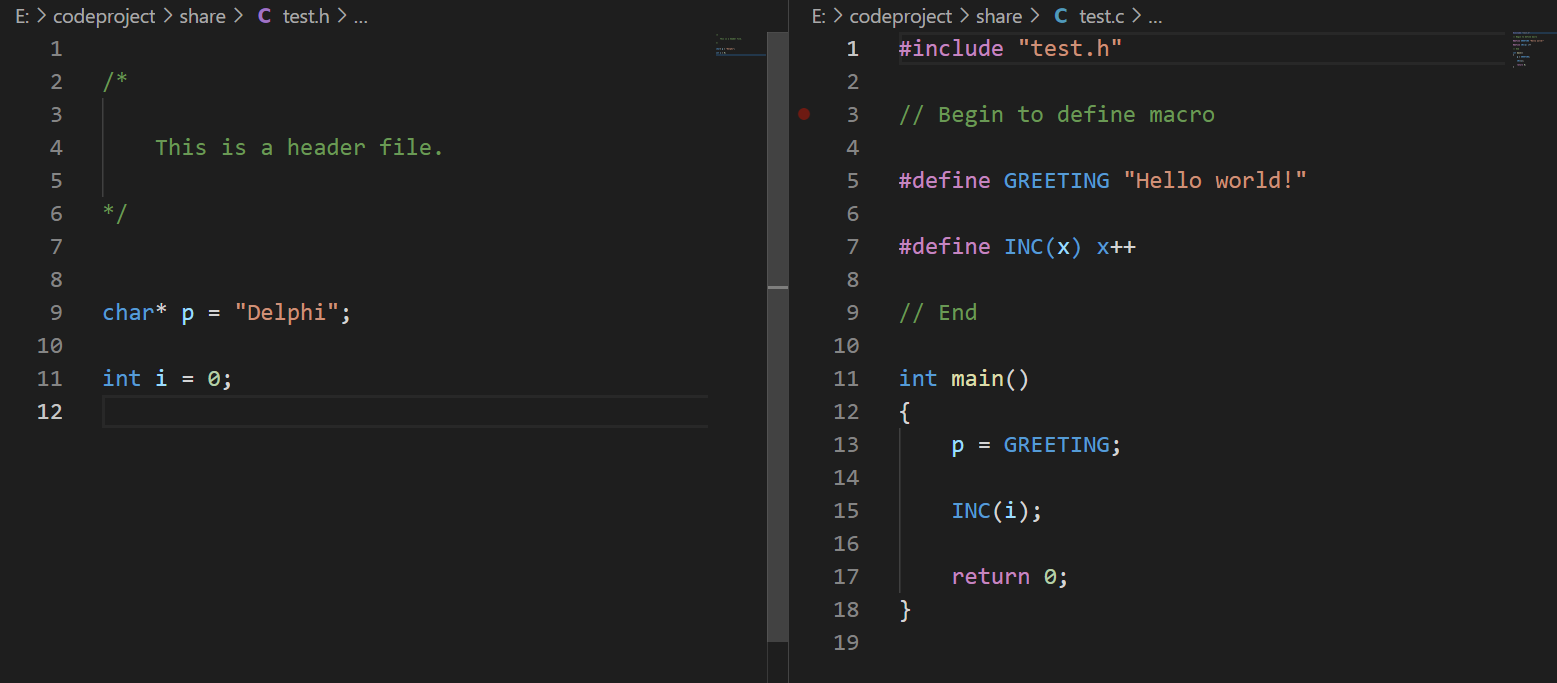
执行gcc -E test.c -o test.i预处理过后,可以观察到
- 注释消失了。
- include头文件test.h里的东西(两个全局变量)原封不动的复制到test.i中了。
- 宏消失了并且宏直接展开全部被替换了。
- 多了#号开头的内容,这些内容是作为传递给后续的编译器的输入内容。
编译
1.对预处理文件进行词法分析,语法分析和语义分析(详情请见编译原理)
- 词法分析:分析关键字,标示符,立即数等是否合法
- 语法分析:分析表达式是否遵循语法规则
- 语义分析:在语法分析的基础上进一步分析表达式是否合法
2.分析结束后进行代码优化生成相应的汇编代码文件
编译指令示例: gcc -S file.c -o file.s
汇编
- 汇编器将汇编代码转变为机器的可以执行指令
- 每条汇编语句几乎都对应一条机器指令
汇编指令示例: gcc-c file.s -o file.o
1 | fengyun@ubuntu:~/share$ gcc -E test.c -o test.i |
test.o不是可执行文件,是一个二进制文件,无法执行。
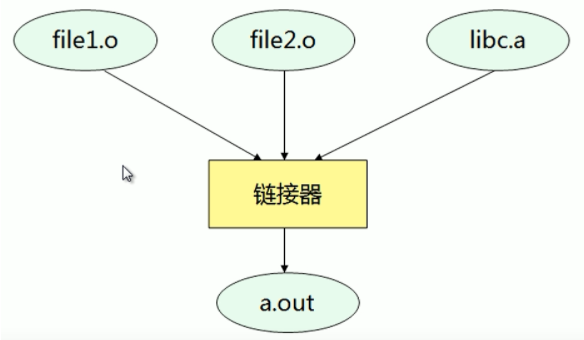
链接
连接器的主要作用是把各个模块之间相互引用的部分处理好,使得各个模块之间能够正确的衔接。
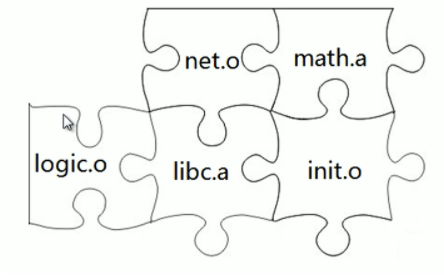
静态链接
由链接器在链接时将库的内容直接加入到可执行程序中。a.out包含file1.o,file2.o,libc.a三个文件,运行的时候与原始的file1.o,file2.o,libc.a三个文件没有任何关系,不需要它们就可以直接运行。
Linux下静态库的创建和使用
编译静态库源码: gcc -c lib.c -o libo
生成静态库文件: ar -q lib.a lib.o
使用静态库编译: gcc main.c lib.a -o main.out
1 | fengyun@ubuntu:~/share$ gcc -c slib.c -o slib.o |
Linux ar命令用于建立或修改备存文件,或是从备存文件中抽取文件。
ar可让您集合许多文件,成为单一的备存文件。在备存文件中,所有成员文件皆保有原来的属性与权限。
动态链接
- 可执行程序在运行时才动态加载库进行链接
- 库的内容不会进入可执行程序当中
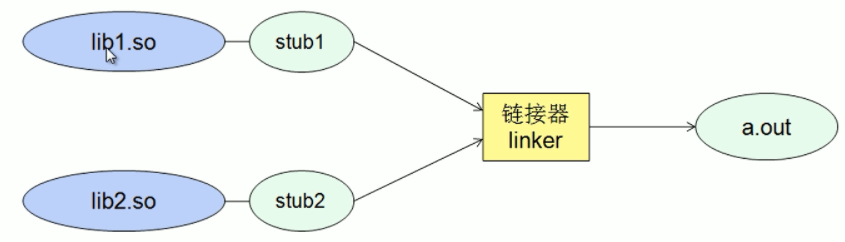
lib1.so和lib2.so动态库生成的stub1和stub2,是最终生成的可执行程序可以使用的内容,程序看不到其它内容。
Linux下动态库的创建和使用
- 编译动态库源码: gcc -shared dlib.c -o dlib.so
- 使用动态库编译: gcc main.c -Idl -o main.out
- 关键系统调用
dlopen:打开动态库文件
dIsym:查找动态库中的函数并返回调用地址
dlclose:关闭动态库文件
1 | fengyun@ubuntu:~/share$ gcc -shared dlib.c -o dlib.so |
删除库文件之后,运行失败。
1 | fengyun@ubuntu:~/share$ rm dlib.so |
动态链接和静态链接根据用户不同需求而产生的。比如部分更新需要动态链接,一些小程序通常静态链接。
总结
编译过程分为预处理,编译,汇编和链接四个阶段
预处理:处理注释,宏以及已经以#开头的符号
编译:进行词法分析,语法分析和语义分析等
汇编:将汇编代码翻译为机器指令的目标文件
链接是指将目标文件最终链接为可执行程序
根据链接方式的不同,链接过程可以分为:1.静态链接:目标文件直接链接进入可执行程序。2.动态链接:在程序启动后才动态加载目标文件
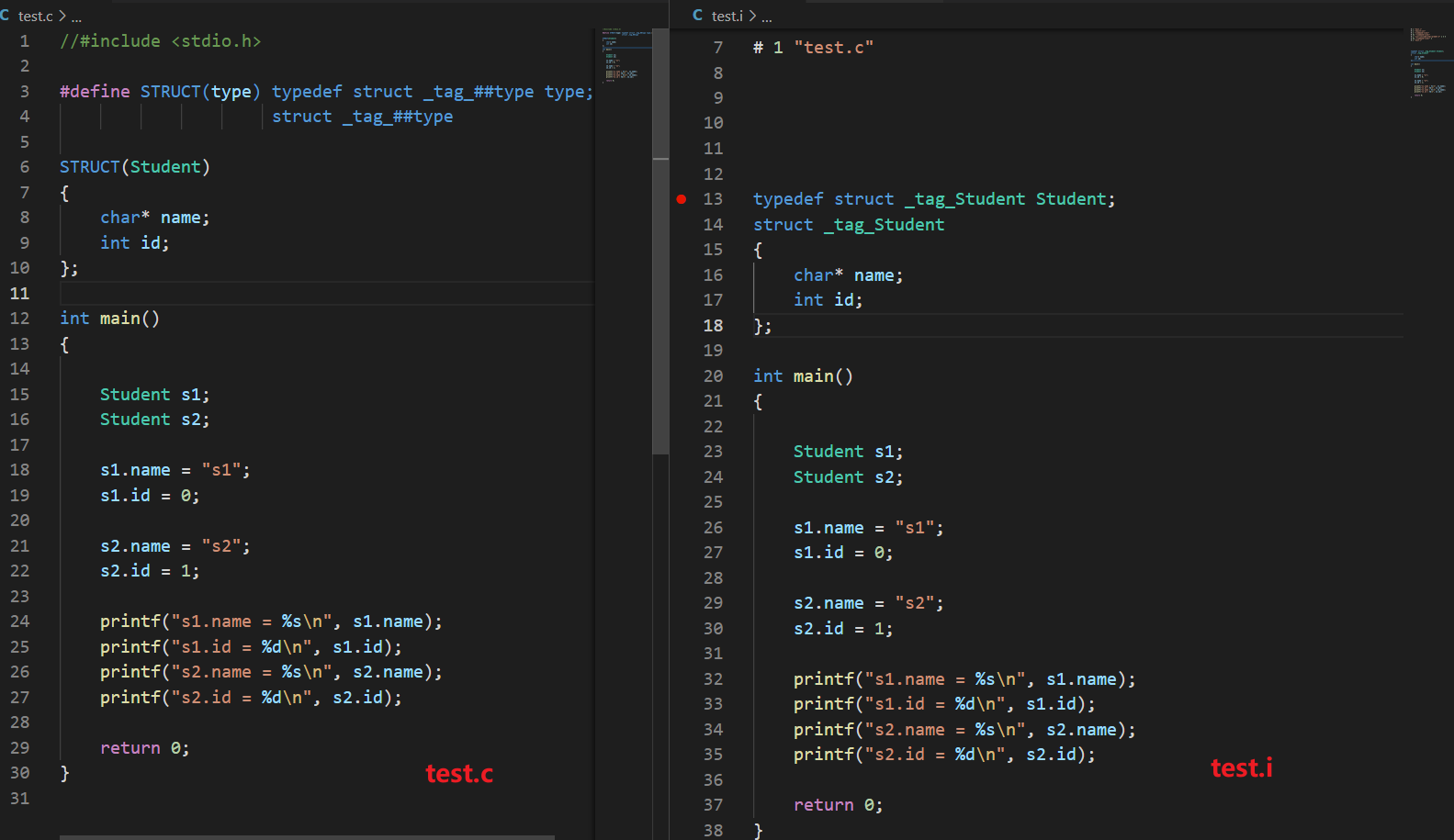
宏定义与使用分析
- #define是预处理器处理的单元实体之一
- #define定义的宏可以出现在程序的任意位置
- #define定义之后的代码都可以使用这个宏
- #define定义的宏常量可以直接使用
- #define定义的宏常量本质为字面量
1 |
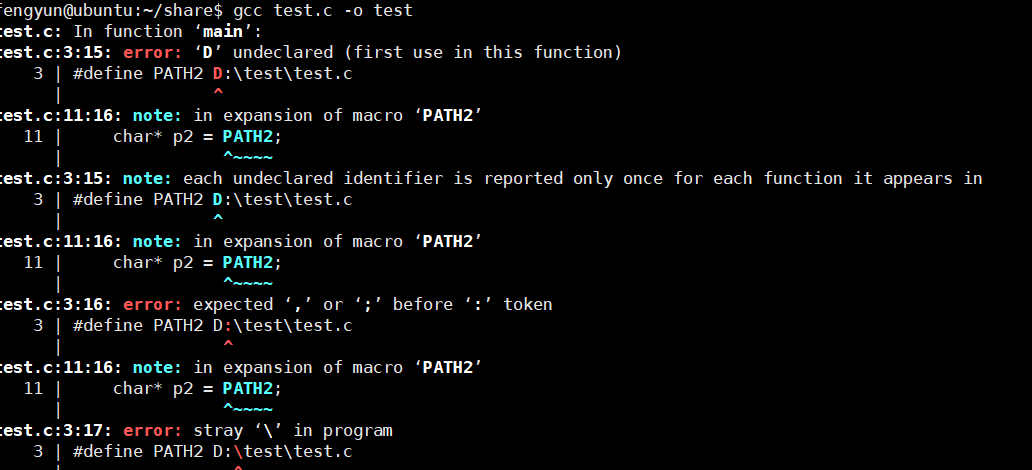
以上四个宏定义:对对错错
define字面量不占用内存,const常量是一个变量占用内存,,本质区别。
1 | fengyun@ubuntu:~/share$ gcc -E test.c -o test.i |
预编译过程预处理器并未报错,预处理器并不会进行语法检查。
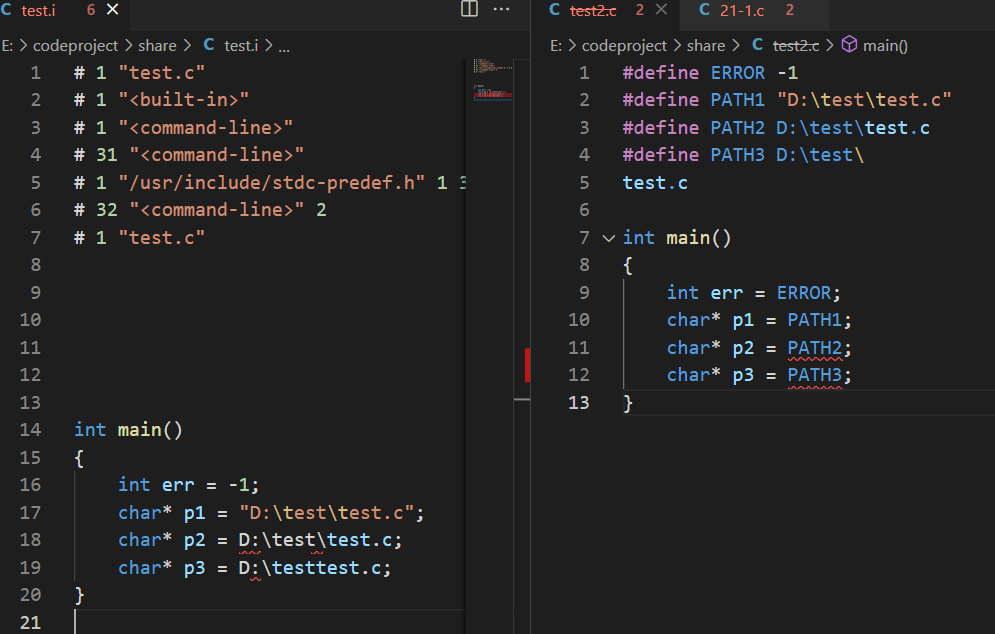
如果直接编译那么会出错,字面量不符合C语言的语法规则。
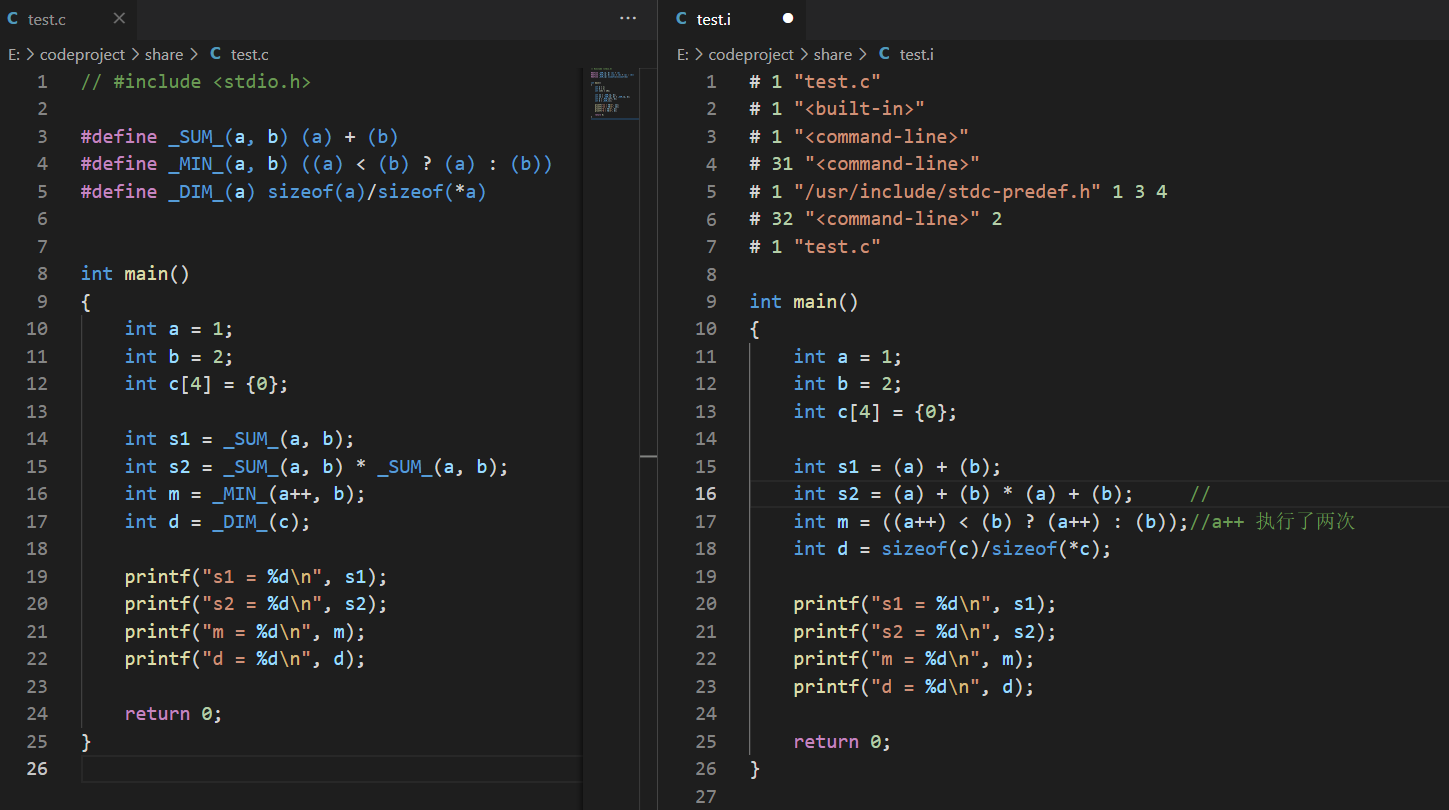
- #define表达式的使用类似函数调用
- #define表达式可以比函数更强大
- #define表达式比函数更容易出错
1 |
求解数组的大小,这个用函数很难做到。
1 | fengyun@ubuntu:~/share$ ./test |
宏表达式与函数比对
- 宏表达式被预处理器处理,编译器不知道宏表达式的存在
- 宏表达式用“实参”完全替代形参,不进行任何运算
- 宏表达式没有任何的“调用”开销
- 宏表达式中不能出现递归定义
1 |
|
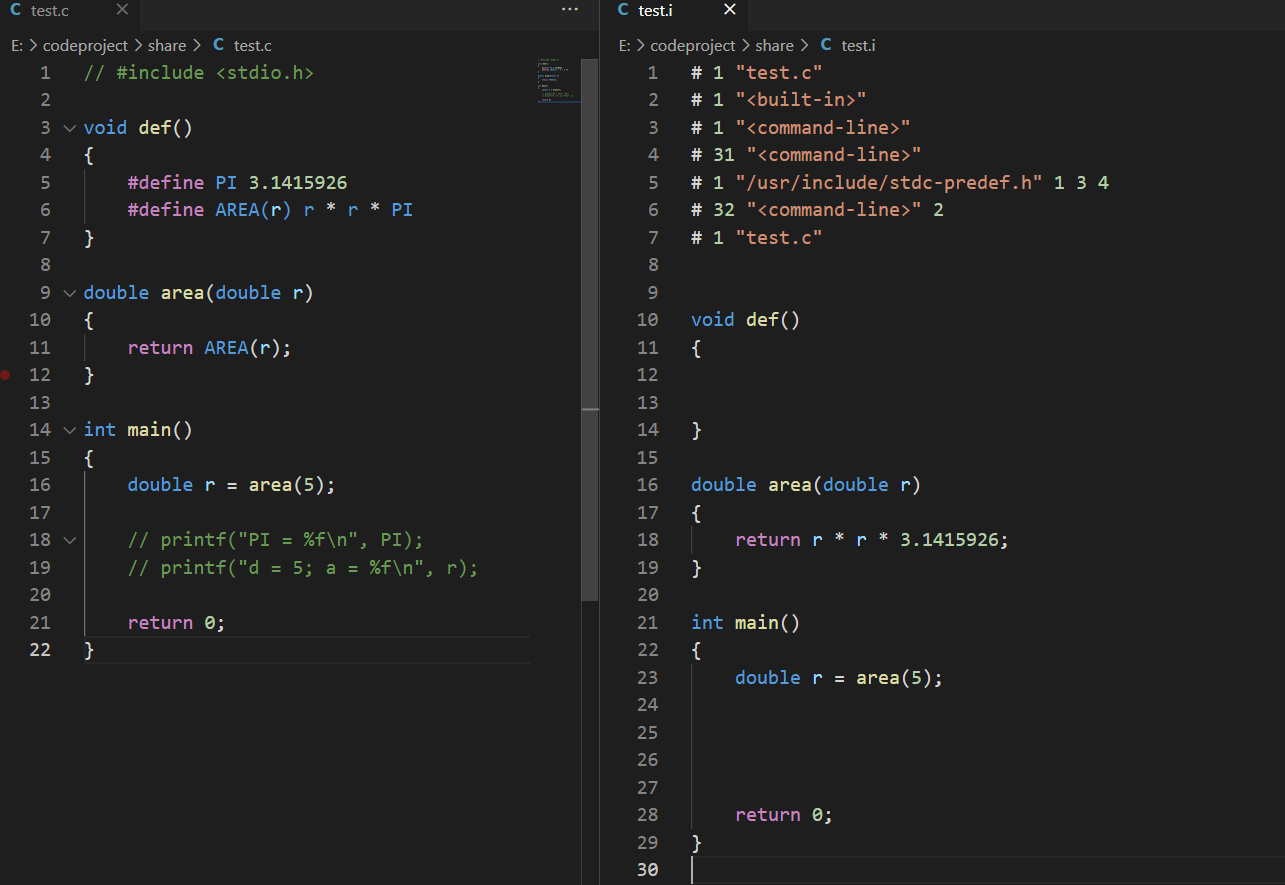
宏没有作用域
1 | fengyun@ubuntu:~/share$ gcc -E test.c -o test.i |
一个本应报错的程序却并没有报错,因为宏不存在定义域。
强大的内置宏
宏应用
对于C语言的函数无法办到以下宏实现的功能。
1 |
|
1 | fengyun@ubuntu:~/share$ ./test |
小结
- 预处理器直接对宏进行文本替换
- 宏使用时的参数不会进行求值和运算
- 预处理器不会对宏定义进行语法检查
- 宏定义时出现的语法错误只能被编译器检测
- 宏定义的效率高于函数调用
- 宏的使用会带来一定的副作用
条件编译使用分析
条件编译的行为类似于C语言中的if..else…
条件编译时预编译指示命令,用于控制是否编译某段代码
执行gcc -E test.c -o test.i并且查看test.i
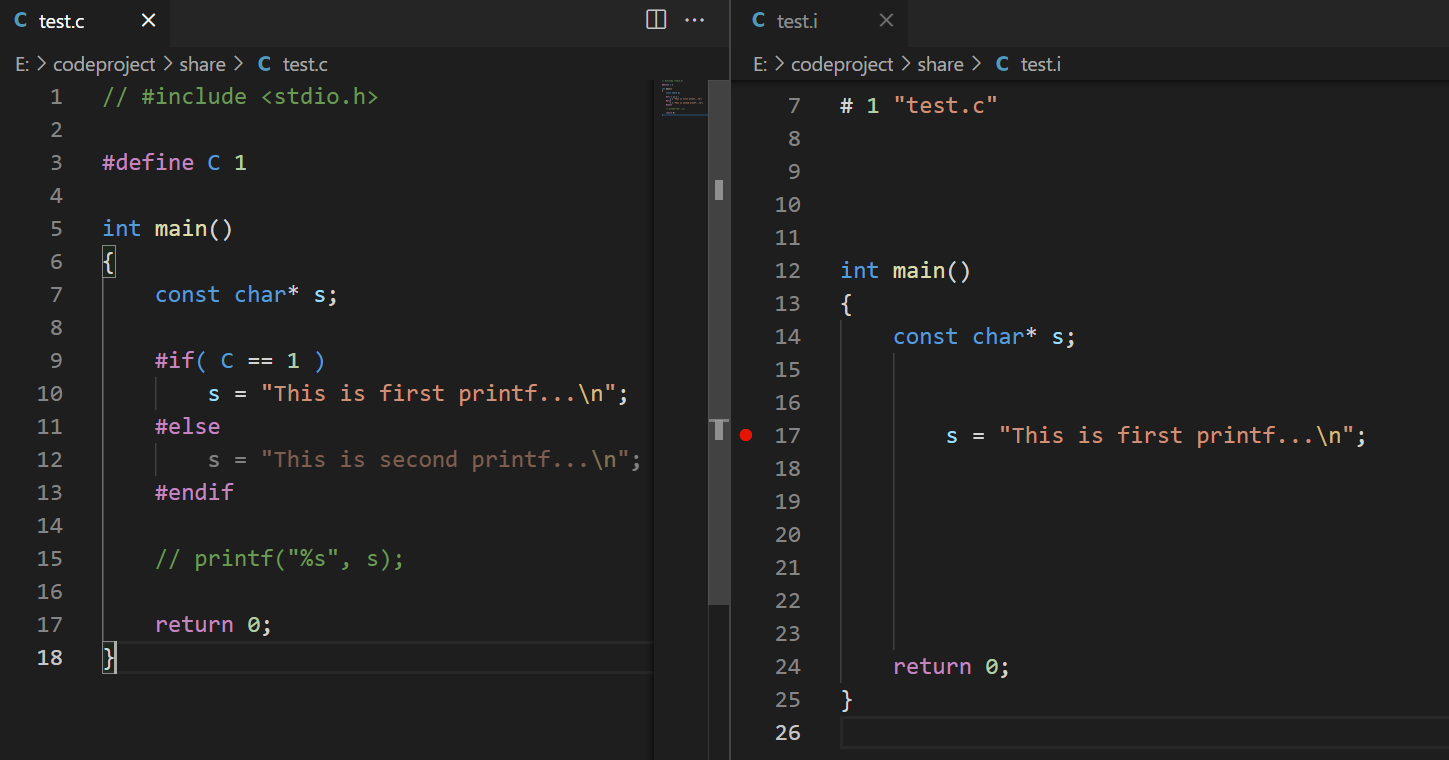
条件编译的本质
- 预编译器根据条件编译指令有选择的删除代码
- 编译器不知道代码分支的存在
- if…else…语句在运行期进行分支判断
- 条件编译指令在预编译期进行分支判断
- 可以通过命令行定义宏
1 | gcc -Dmacro=value file.c |
我把上面的test.c文件中#define C 1语句删除。改为命令行定义宏,观察输出结果仍然相同。
1 | fengyun@ubuntu:~/share$ gcc -DC=1 test.c -o test |
#include的本质
- 本质是将已经存在的文件内容嵌入到当前文件中
- 间接包含同样会产生嵌入文件内容的操作
例如#include<stdio.h>告诉预处理器要将当前代码调整,将stdio.h文件所有内容都复制到当前文件里面来。
可能存在重复定义的情况比如我有这样三个文件:
test.c如下:
1 |
|
global.h如下
1 | int global = 10; |
test.h如下:
1 |
注意test.h已经包含了global.h,test.c也包含了global.h,这样的话test.c预编译结果中会有两条int global = 10;
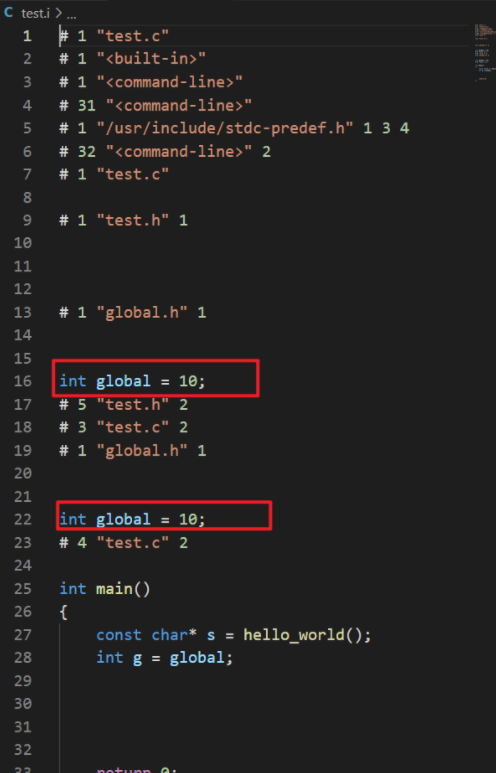
如果编译运行会产生错误。
解决方法是添加条件编译
global.h中添加宏判断,第一次处理的时候int global = 10;会保留下来,第二次又来读取的时候就会删除。
1 |
|
1 |
条件编译的意义
- 条件编译使得我们可以按照不同的条件编译不同的代码段,删除或保留我们想要的代码
- #if…#else…#endif被预编译器处理,而if…else…语句被编译器处理会被编译进目标代码
- 实际工程条件编译用途:
不同产品线共用同一份代码
区分编译产品的调试版和发布版
工程开发模型
product.h如下,设置产品是发布版或调试版
1 |
1 |
|
#error
#error用于生成一个编译错误消息
用法: #error message
message不需要用双引号包围
#error编译指示字用于自定义程序员特有的编译错误消息
类似的,#waring用于生成编译警告
#error是一种预编译指示字,可用于提示编译条件是否满足
例如,__cplusplus是C++特有的一个宏,如果我们用的编译器不支持C++那么是不会预定义这个宏,运行的时候将会打印提示信息
1 |
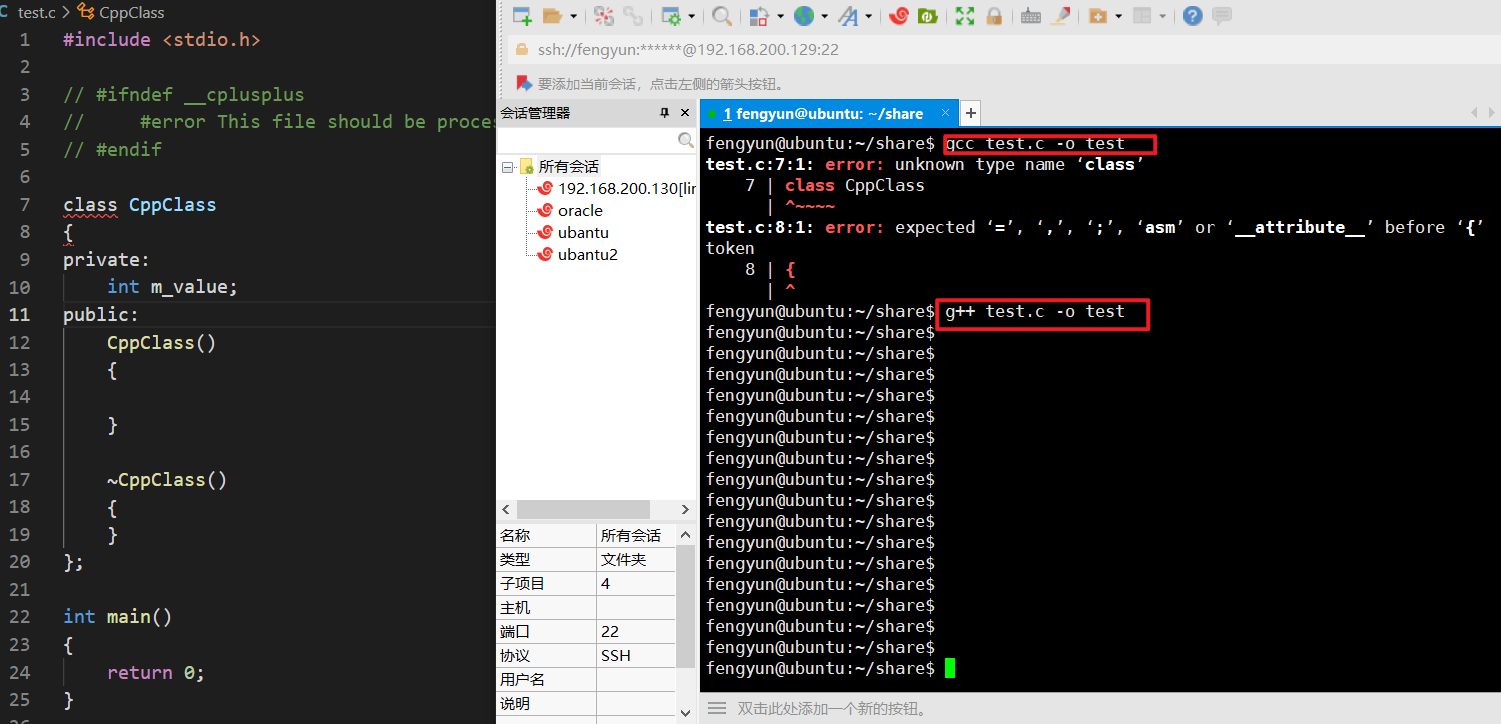
如图所示,gcc编译器报了许多错误。
而我们加上__cplusplus宏定义判断后,会打印我们自己定义的错误信息—即This file should be processed with C++ compiler.
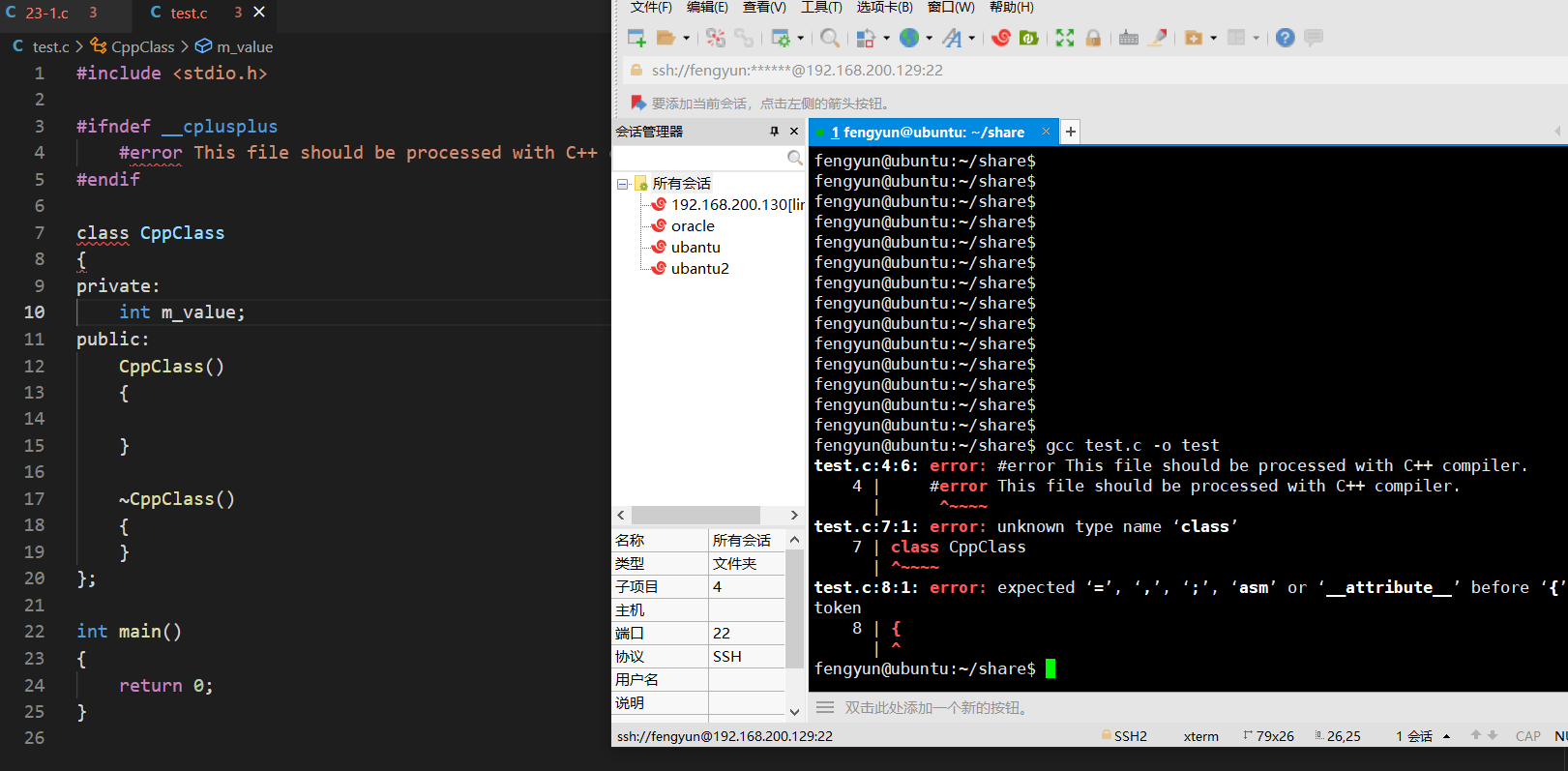
在实际工程开发中,如下所示,未定义宏PRODUCT直接gcc test.c -o test如果缺少#error打印信息那么会导致功能不完备,添加打印信息后会提示用户定义PRODUCT。
1 |
|
如果将#error改为#warning后,编译仍然会产生warning信息但是仍然会生成可执行文件。
#line
#line用于强制指定新的行号和编译文件名,并对源程序的代码重新编号
用法:#line number filename
filename可省略
#line 编译指示字的本质是重定义__LINE__和__FILE__
1 |
|
1 | fengyun@ubuntu:~/share$ gcc test.c -o test |
#progma
- #progma用于指示编译器完成一些特定的动作
- #progma所定义的很多指示字是编译器特有的
- #progma在不同的编译器间是不可移植的
预处理器将忽略他不认识的#progma指令 不同的编译器可能以不同方式解释同一条#progma指令
一般用法:#progma parameter
不同的parameter参数语法和意义各不相同
#progma message
- message参数在大多数的编译器中都有相似的实现
- message参数在编译时输出消息到编译输出窗口中
- message用于条件编译中可提示代码的版本信息
1 |
与#error和#warning不同,#progma message仅仅代表一条编译消息,不代表代码有任何问题。


#progma once
#progma once用于保证头文件制备编译一次
#progma once时编译器相关的,不一定被支持。

第一种方式是被C语言支持的,通过宏来控制头文件内容只嵌入一次,预处理器仍然处理了多次。
第二种方式#pragma once告诉编译器只需要编译一次即可,预处理器只需会处理一次,效率更高。
既保证一次性又保证效率
1 |
|
#progma pack
什么是内存对齐?
- 不同类型的数据在内存中按照一定的规则排列
- 而不一定是顺序的一个接一个的排列

执行sizeof打印两个test结构体的大小的程序
1 | fengyun@ubuntu:~/share$ ./test |
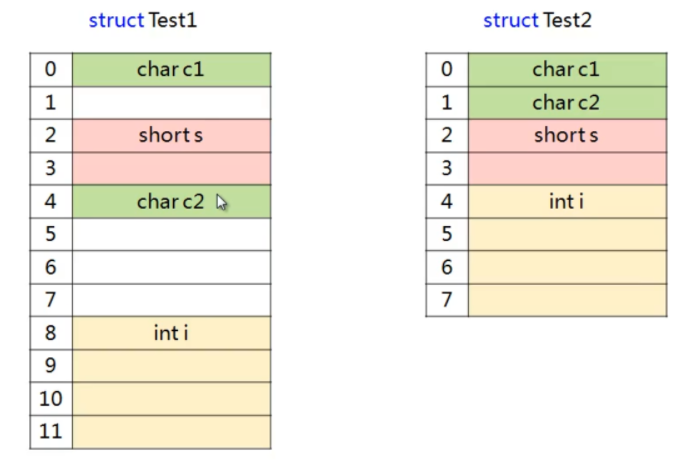
为什么内存对齐?
- CPU对内存的读取不是连续的,而是分块读取的,块的大小只能是1,2,4,8,16…字节
- 当读取操作的数据未对齐,则需要两次总线周期来访问内存,因此性能会大打折扣
- 某些硬件平台只能从规定相对地址处读取特定类型的数据,否则产生硬件异常

**注意是#pragma pack (1)**。
1 | fengyun@ubuntu:~/share$ ./test |
stuct占用内存大小
1.第一个成员起始于 0偏移处
2.每个成员按照类型大小和pack参数中较小的一个对齐
偏移地址必须能够被对齐参数整除
结构体成员的大小取其内部长度最大的数据成员作为其大小
3.结构体总长度必须为所有对齐参数的整数倍
4.编译器在默认情况下按照4字节对齐 (即默认#progma pack(4))

一道微软面试题
先算对齐参数min(pack,size),再计算偏移地址(能够被对齐参数整除)
1 |
|
s1和s2大小分别为8字节和24字节。
#运算符和##运算符
#运算符
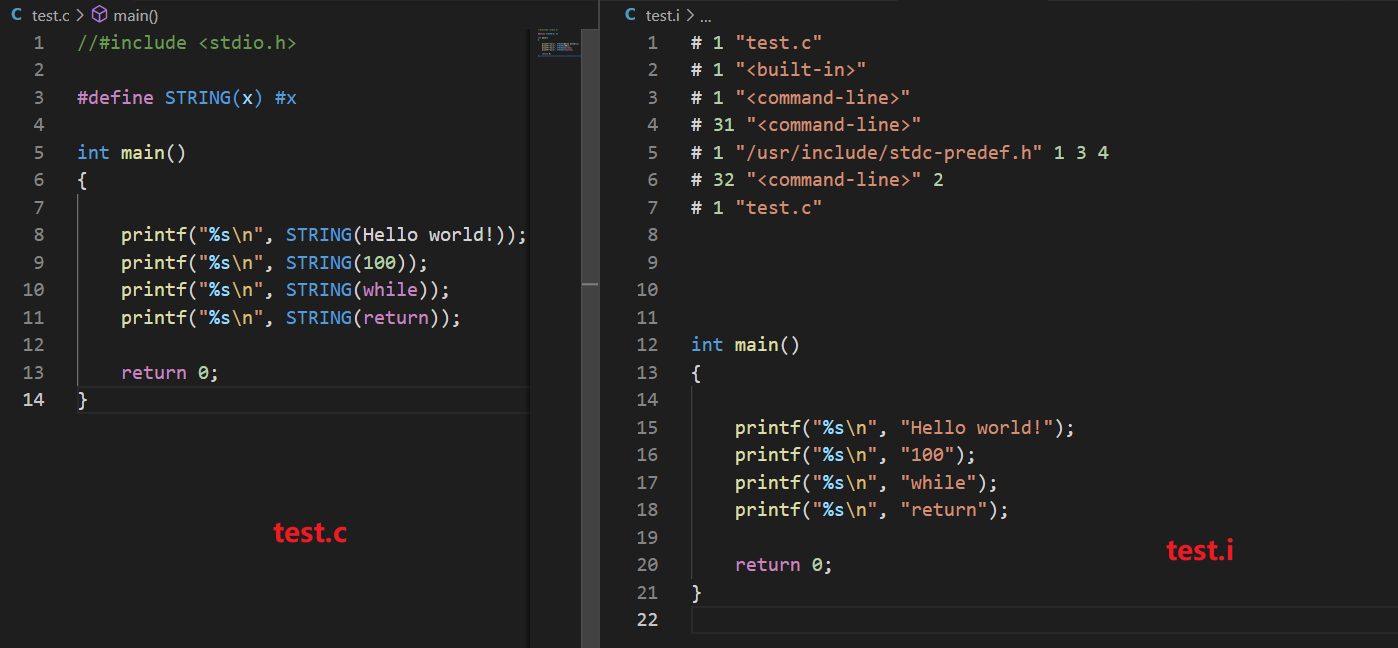
- #运算符用于在预处理期将宏参数转换为字符串
- #的转换作用是在预处理期完成的,因此只在宏定义中有效
- 编译器是不知道#的转换作用的。
- 用法:
1 |
|
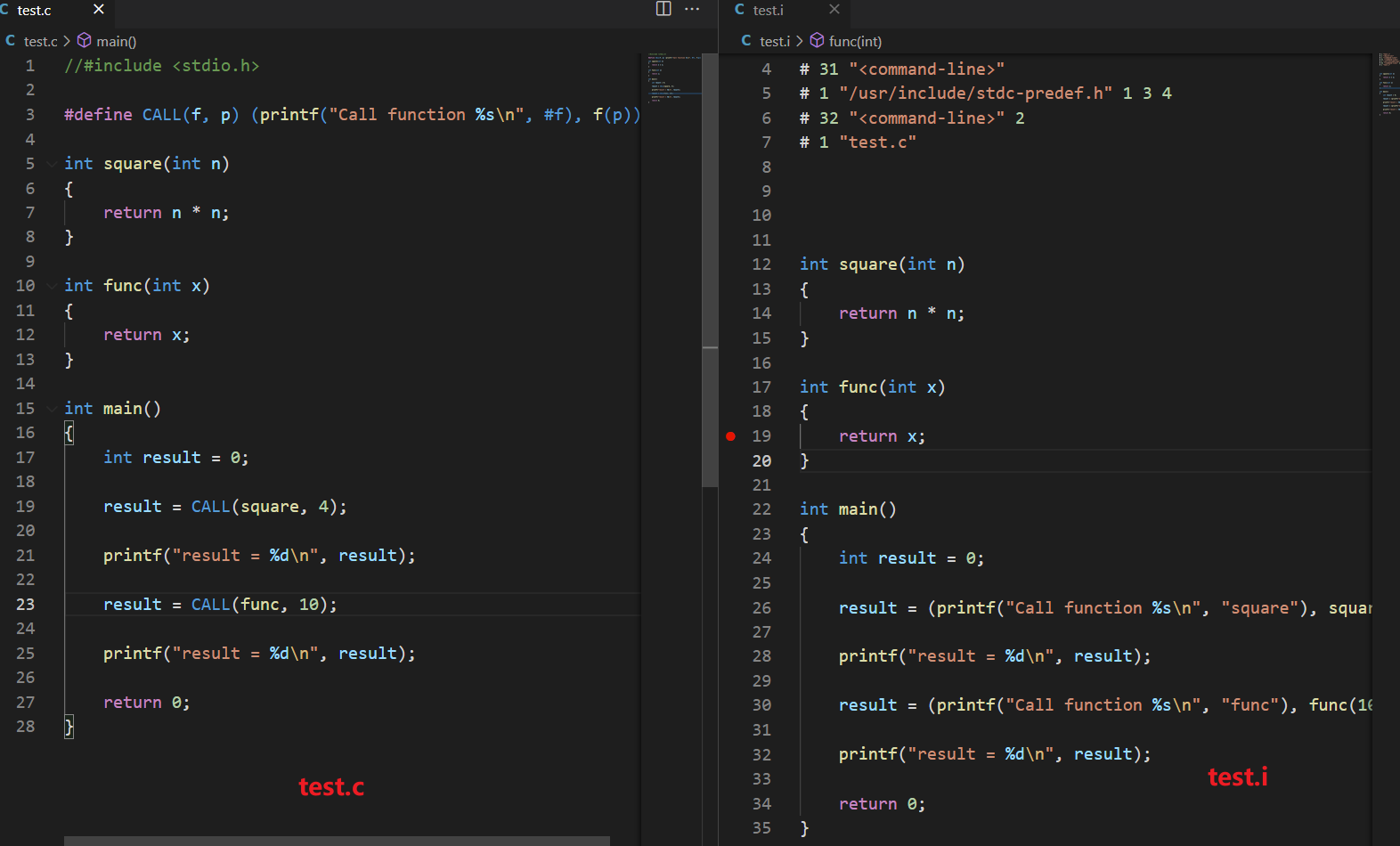
动态的知道函数的函数名,用#运算符转换。
1 |
|
1 | fengyun@ubuntu:~/share$ gcc test.c -o test |
##运算符
- ##运算符用于在预处理器粘连两个标识符
- ##的连接作用是在预处理期完成的,因此只在宏定义中有效
- 编译器不知道##的连接作用
- 用法

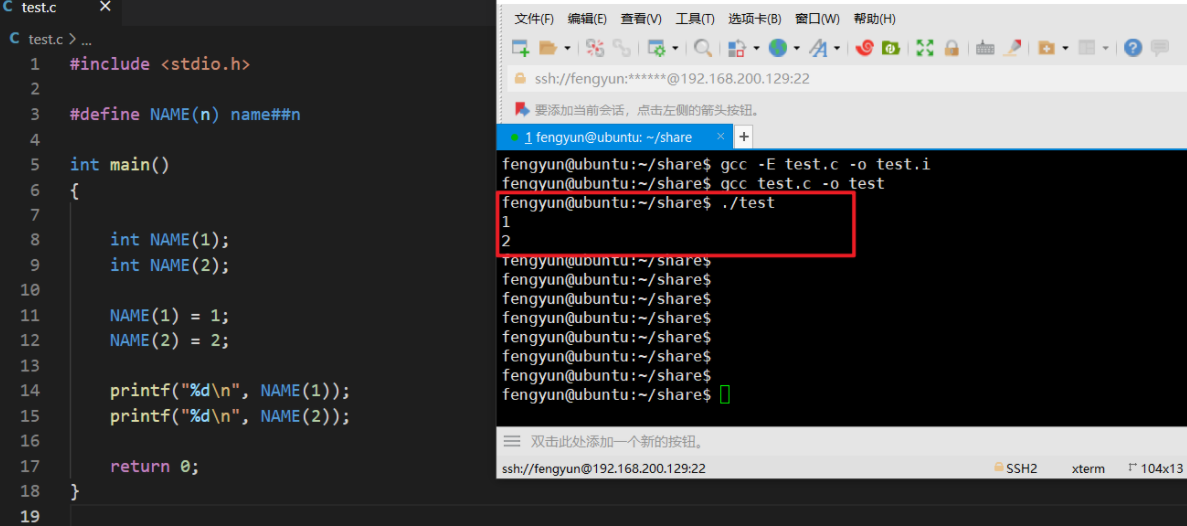
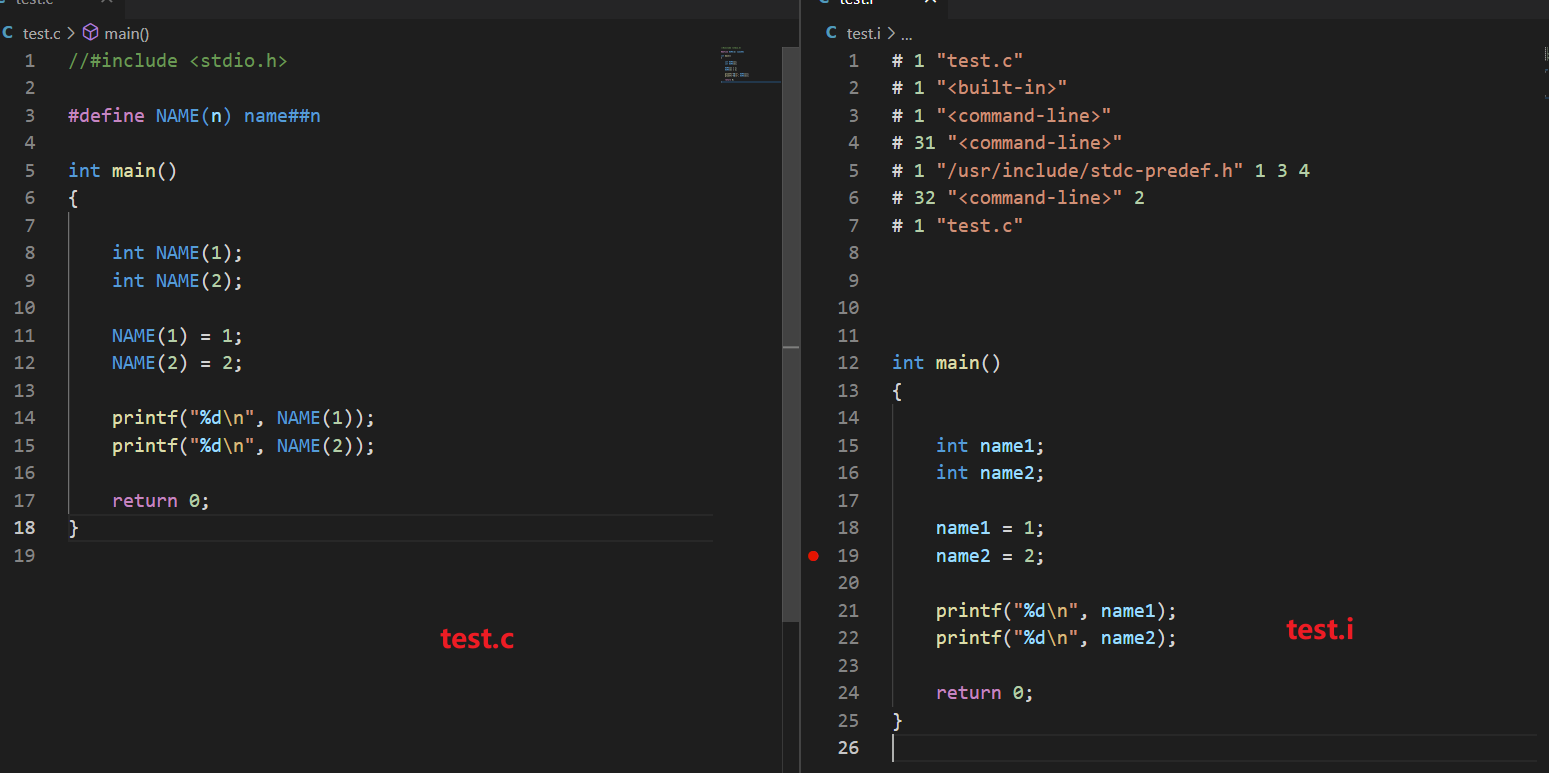
##运算符解决在工程代码里定义成百上千个结构体。
创建一个结构体,并且用typedef给结构起别名。将这两个操作合二为一,非##宏定义莫属。