排序算法
排序的基本概念
排序的一般定义
排序是计算机内经常进行的一种操作,其目的是将一组 “无序” 的数据元素调整为“有序”的数据元素。
例如 : 将下列关键字序列
52, 49, 80, 36, 14, 58, 61, 23, 97, 75
调整为:
14, 23, 36, 49, 52, 58, 61,75, 80, 97
排序的数学定义 假设含 n 个数据元素的序列为 : { R1,R2,…,Rn } , 其 相应的关键字序列为 : { K1,K2, …Kn};
这些关键字相互之间可以进行比较,即 : 在它们之间存在着这样关系 :
Kp1 <= Kp2 <= … <= Kpn
按此固有关系将上式记录重新排列为 :
{Rp1,Rp2,…,Rpn }
的操作称为排序。
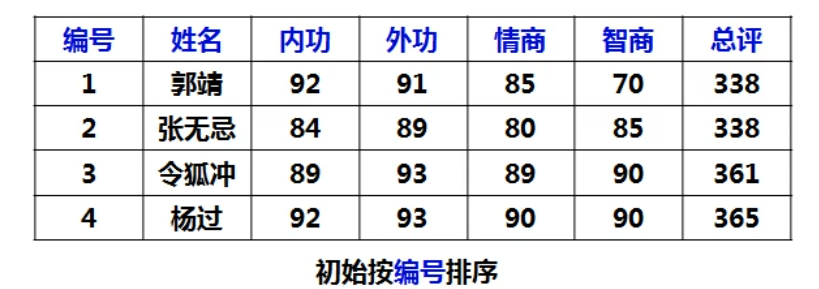
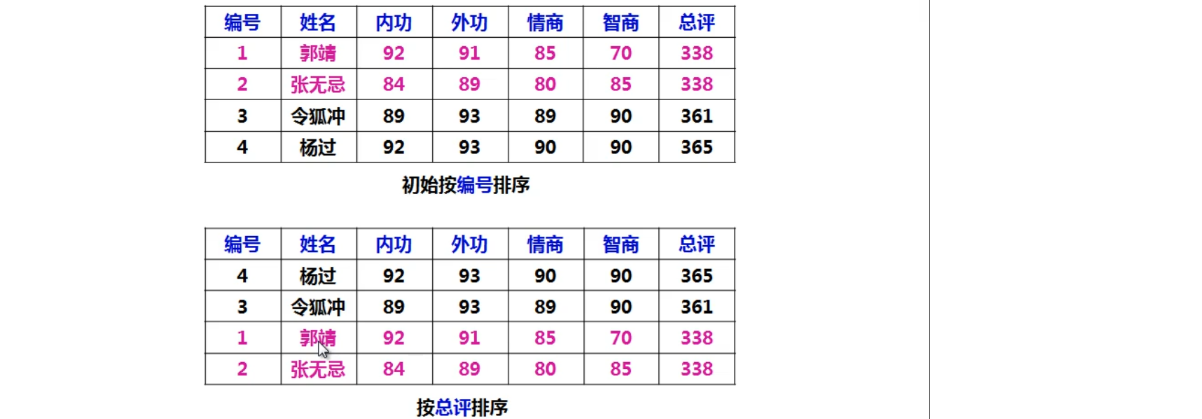
关键字是编号,按照编号排序。
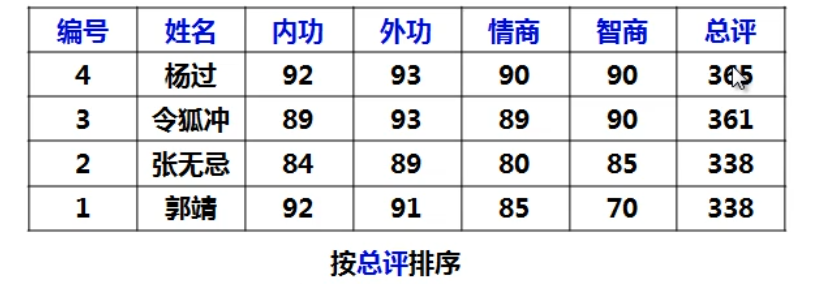
关键字是总评,按照总评排序。
但是按总评排序后为什么张无忌的排名比郭靖靠前呢 ?
排序的稳定性
通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。. 在简单形式化一下,如果Ai = Aj, Ai原来在位置前,排序后Ai还是要在Aj位置前。
排序方法是要么是稳定的,要么是不稳定的。
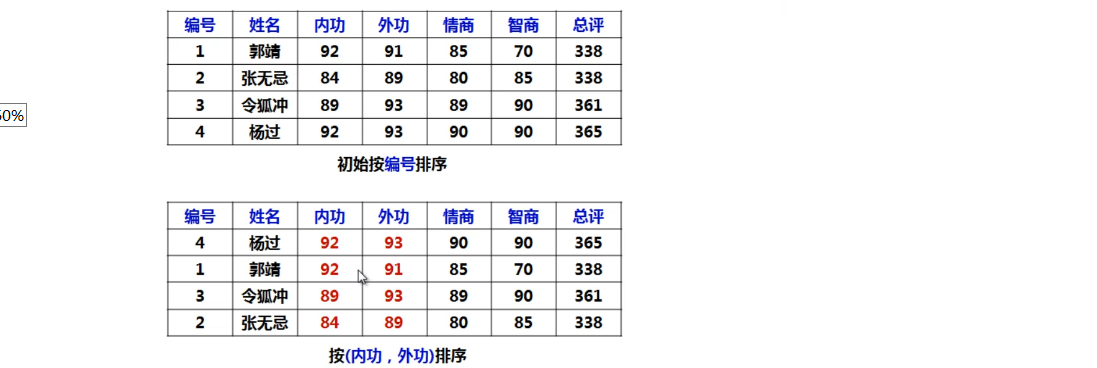
多关键字排序
排序时需要比较的关键字多余一个且优先级各不相同
- 当排序结果首先按关键字1进行排序
- 当关键字1相同时按关键字2进行排序
- …….
- 当关键字n-1相同时按关键字n进行排序
1 | struct Test |
排序中的关键操作
比较–任意两个数据元素通过腿操作确定先后次序
交换–数据元素之间需要交换才能得到预期结果
排序的审判
时间性能
• 关键注能差异体现在比较和交换的数量
辅助存储空间
• 为完成排序操作需要的额外的存储空间
• 必要时可以 “空间换时间”
算法的实现复杂性
• 过于复杂的排序法可能影响可读注和可维护性
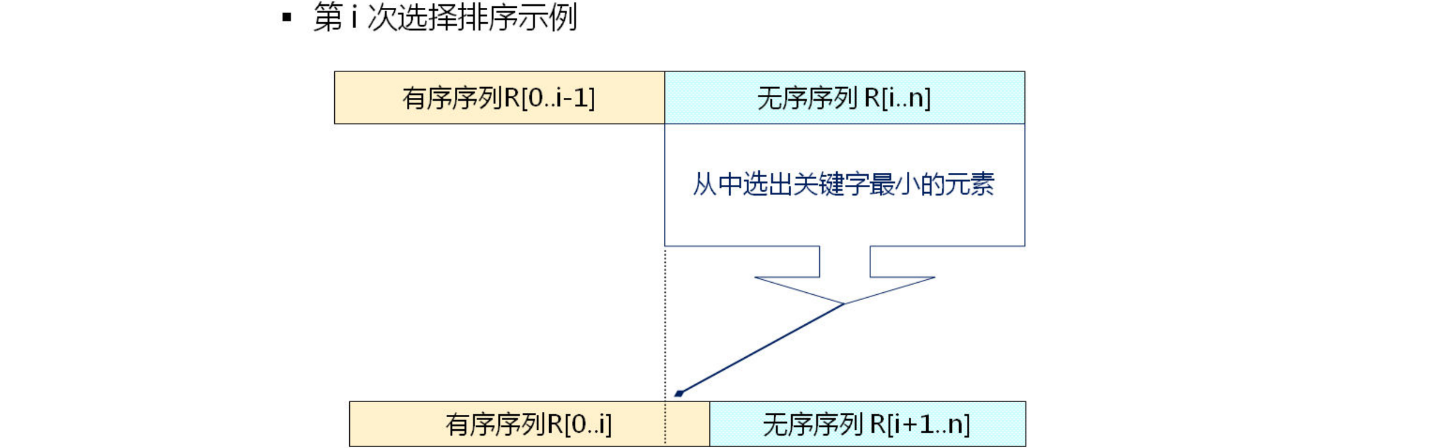
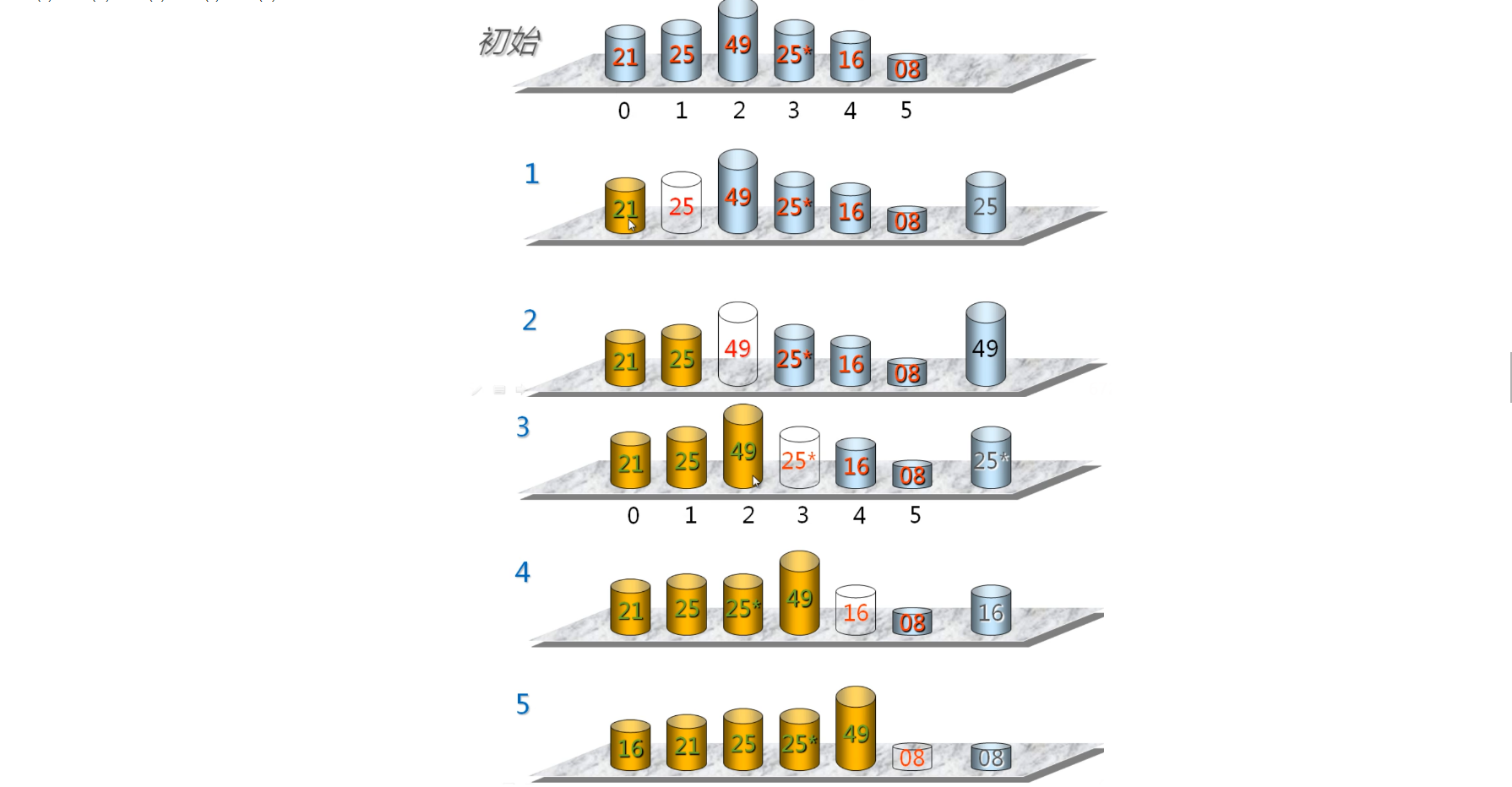
选择排序
选择排序的基本思想
每次(例如第 i 次 , i = 0,1, n-2) 从后面 n-i 个待排的数据元素中选出关键字最小的元素,作为有序元素序列第 i个元素。
1 | template <typename T> |
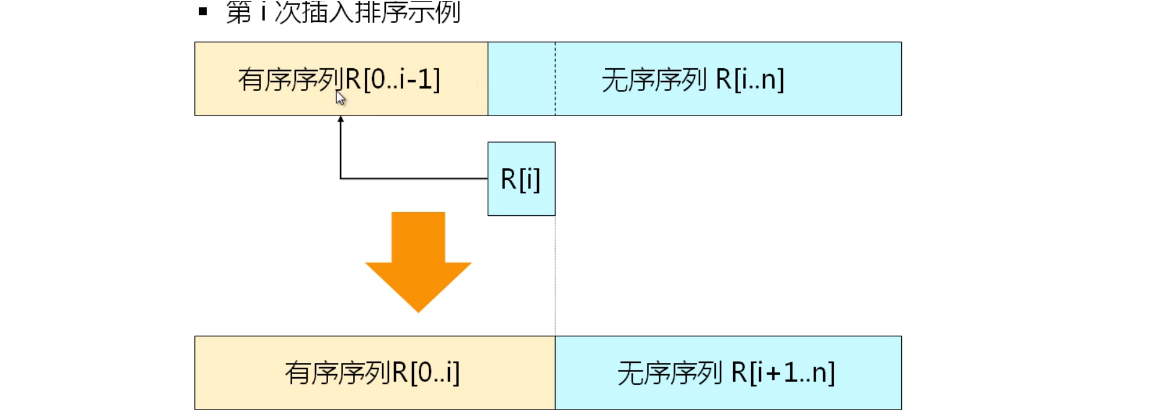
插入排序
插入排序的基本思想
当插入第 i (i >= 1) 个数据元素时 , 前面的 V[0] ,V[l] , ,V[i-1] 已经排好序 ; 这时 , 用 V[i] 的关键字与 V[i-l] ,V[i-2] , ,V[0] 的关键字进行比较 , 找到位置后将 V[i] 插入 ,原来位置上的对象向后顺移。
1 | template <typename T> |
小结:
- 选择排序每次选择未排元素中的最小元素
- 插入排序每次将第 i 个元素插入前面 i - 1 个已排元素中
- 选择排序是不稳定的排序法 , 插入排序是稳定的排序方法
- 选择排序和插入排序的时间复杂度为 0(n2 )
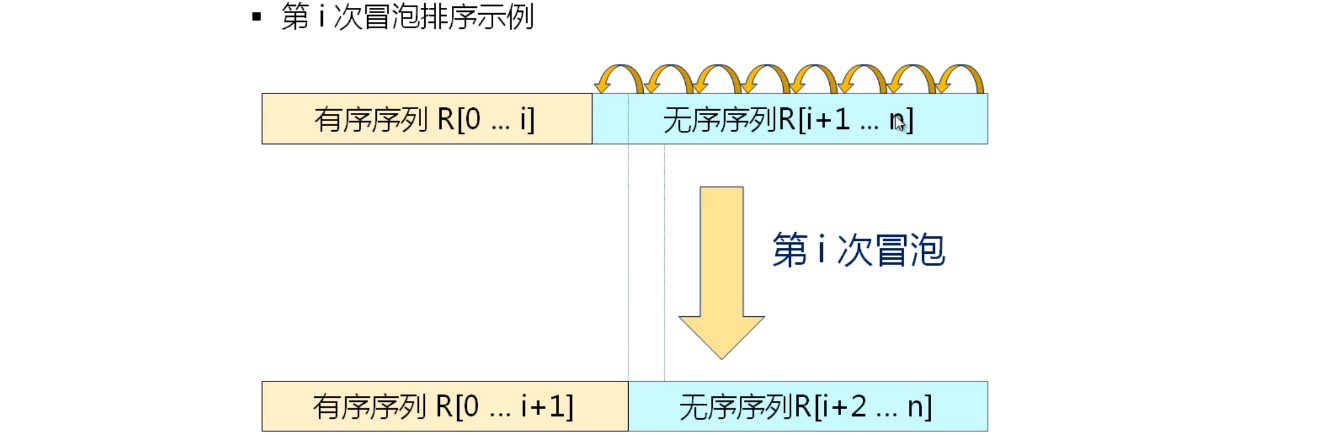
冒泡排序
冒泡排序的基本思想
- 每次从后向前进行( 假设为第 i 次 ) j = n-1,n-2, …, i ,两两比较 V[j-1] 和 V[j] 的关键字;如果发生逆序,则交换V[j-1] 和 V[j] 。
例如,对无序表{49,38,65,97,76,13,27,49}进行升序排序的具体实现过程如
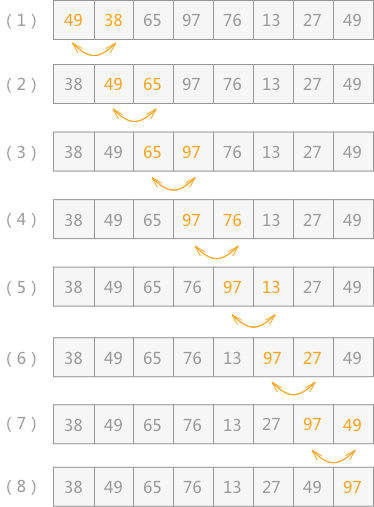
如图 1 所示是对无序表的第一次起泡排序,最终将无序表中的最大值 97 找到并存储在表的最后一个位置。具体实现过程为:
- 首先 49 和 38 比较,由于 38<49,所以两者交换位置,即从(1)到(2)的转变;
- 然后继续下标为 1 的同下标为 2 的进行比较,由于 49<65,所以不移动位置,(3)中 65 同 97 比较得知,两者也不需要移动位置;
- 直至(4),97 同 76 进行比较,76<97,两者交换位置,如(5)所示;
- 同样 97>13(5)、97>27(6)、97>49(7),所以经过一次冒泡排序,最终在无序表中找到一个最大值 97,第一次冒泡结束;
1 | template <typename T> |
希尔排序
希尔排序的基本思想
- 将待排序列划分为若干组 , 在每一组内进行插入排序 , 以使整个序列基本有序 , 然后再对整个序列进行插入排序。
希尔当时发现待排元素个数非常小的时候插入排序非常快,而如果一个待排元素序列基本有序的时候插入排序也非常快。于是他将这两个思想结合在一起,多做几次插入排序时间是不是会变得更加地快?(闪烁着人性地智慧QWQ)
经过多次实验,时间复杂度真的变低了,具体可以查看《算法导论》证明
1 | template <typename T> |
只需分好组,组内排序直接用选择排序即可。
那么如何分组,组之间d = d/3 + 1;这样排序速度最快。
- 冒泡排序每次从后向前将较小的元素交互到位
- 冒泡排序是一种稳定的排序法 , 其复杂度为 0(n2)
- 希尔排序通过分组的方式进行多次插入排序
- 希尔排序是一种不稳定的排序法 , 其复杂度为 0(n3/2)
归并排序
归并排序的基本思想
将两个或两个以上的有序序列合并成一个新的有序序列
有序序列 v[0] … V[m] 和 V[m+1] … V[n-1]
合并成为V[0] …V[n-1]
这种归并方法称为 2 路归并。
归并的套路
- - 将 3 个有序序列归并为一个新的有序序列 , 称为 3 路归并
- - 将 N 个有序序列归并为一个新的有序序列 , 称为 N 路归并
- - 将多个有序序列归并为一个新的有序序列 , 称为多路归并

我们要让2路归并,但是这2个序列并不是有序的,那么我们可以采用递归,先让这两路有序后再归并成一路有序。
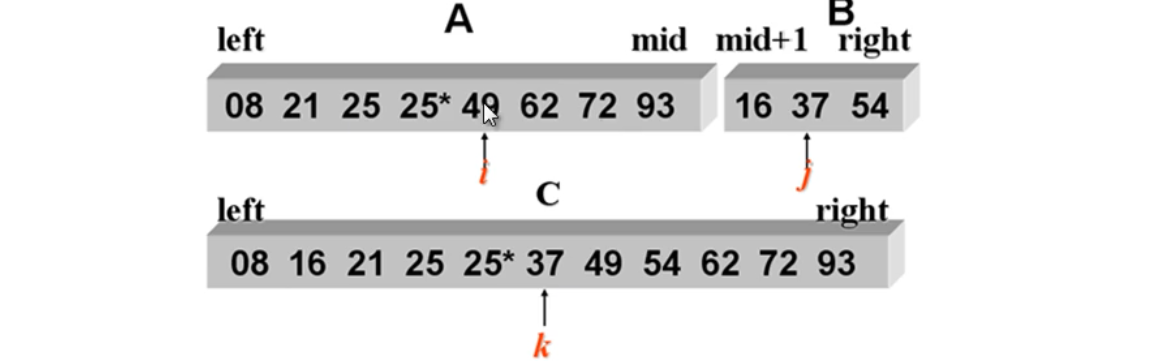
当这两个有序序列需要归并的时候,从代码的角度来看,是放在另一个辅助数组C里面的。最后将辅助数组C的数据再放回原来的位置。
1 | private: |
快速排序
虽然快速排序称为分治法,但分治法这三个字显然无法很好的概括快速排序的全部步骤。因此我的对快速排序作了进一步的说明:挖坑填数+分治法:
先来看实例吧,定义下面再给出(最好能用自己的话来总结定义,这样对实现代码会有帮助)。
以一个数组作为示例,取区间第一个数为基准数。
0 1 2 3 4 5 6 7 8 9 72 6 57 88 60 42 83 73 48 85 初始时,i = 0; j = 9; X = a[i] = 72
由于已经将 a[0] 中的数保存到 X 中,可以理解成在数组 a[0] 上挖了个坑,可以将其它数据填充到这来。
从j开始向前找一个比X小或等于X的数。当j=8,符合条件,将a[8]挖出再填到上一个坑a[0]中。a[0]=a[8]; i++; 这样一个坑a[0]就被搞定了,但又形成了一个新坑a[8],这怎么办了?简单,再找数字来填a[8]这个坑。这次从i开始向后找一个大于X的数,当i=3,符合条件,将a[3]挖出再填到上一个坑中a[8]=a[3]; j–;
数组变为:
0 1 2 3 4 5 6 7 8 9 48 6 57 88 60 42 83 73 88 85 i = 3; j = 7; X=72
再重复上面的步骤,先从后向前找,再从前向后找。
从j开始向前找,当j=5,符合条件,将a[5]挖出填到上一个坑中,a[3] = a[5]; i++;
从i开始向后找,当i=5时,由于i==j退出。
此时,i = j = 5,而a[5]刚好又是上次挖的坑,因此将X填入a[5]。
数组变为:
0 1 2 3 4 5 6 7 8 9 48 6 57 42 60 72 83 73 88 85 可以看出a[5]前面的数字都小于它,a[5]后面的数字都大于它。因此再对a[0…4]和a[6…9]这二个子区间重复上述步骤就可以了。
对挖坑填数进行总结:
- 1.i =L; j = R; 将基准数挖出形成第一个坑a[i]。
- 2.j–由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
- 3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
- 4.再重复执行2,3二步,直到i==j,将基准数填入a[i]中。
1 | template < typename T > |
堆排序
什么是堆?
– 堆是一种特殊的二叉树
• 特殊之处:完全二叉树,每个结点的值都大于(小于)或等于其子树的结点值
• 最大堆:堆中的最大值出现在根结点处
• 最小堆:堆中的最小值出现在根结点处
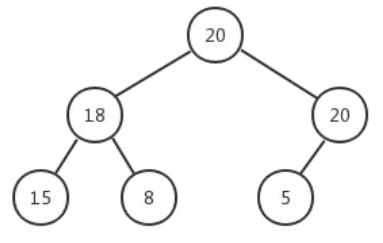
什么是堆?
– 由于堆的最大值 (最小值) 出现在根结点处
– 因此:
• 将堆中根结点处的值取出,将得到堆中最大值 (最小值)
• 此时结构改变,将其重新调整为堆结构
• 次大值 (次小值) 出现于根结点处
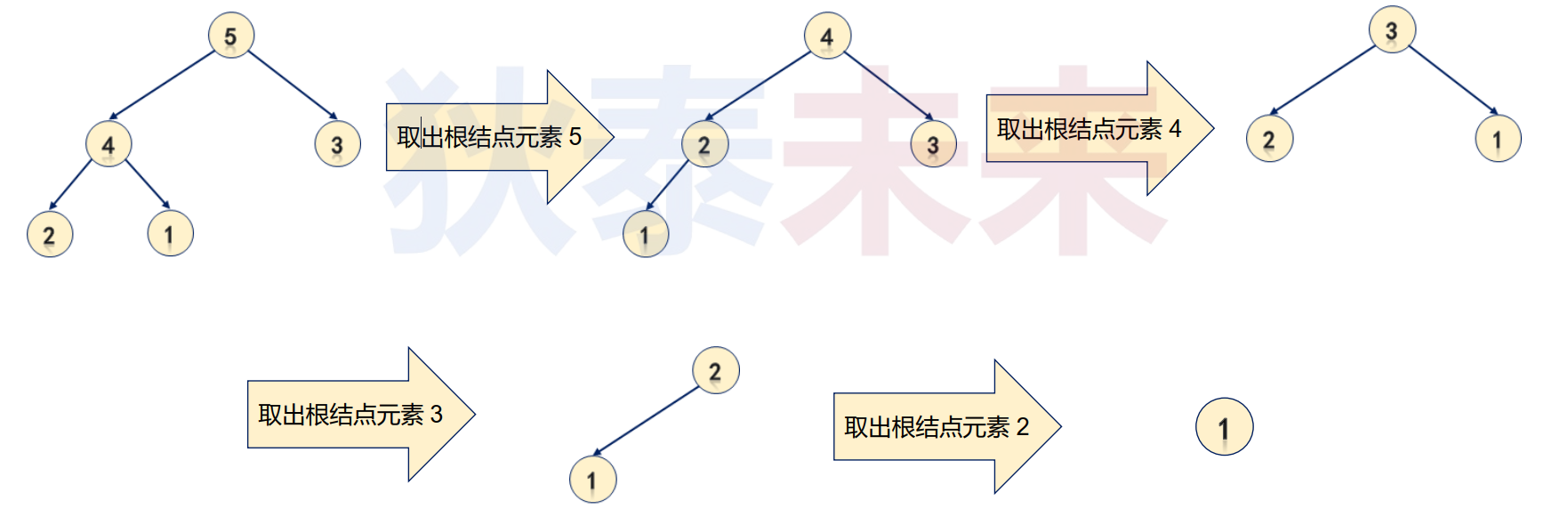
发现的规律
– 可以将一棵完全二叉树调整为堆结构
– 调整后, 数据中的最值出现在根结点处
– 将最值取出,重新调整二叉树成为堆结构
– 二叉树中剩下元素的最值(原次值) 出现在根结点处
什么是堆?
– 堆是一种特殊的线性表,最值出现在线性表头部
– 加入新元素 或 删除队首元素 ,并重新调整线性表为堆
– 则:线性表元素最值再次出现在头部
堆是一种特殊队列 即:优先级队列
堆是一种混血数据结构,既有完全二叉树的特质,又有队列的特质。
堆调整算法思想
– 顺序结构二叉树(线性结构)调整为最大堆结构
• 自底向上进行调整: i = bt.count() / 2
• 若当前结点元素值:
比 左/右 孩子大,则无需调整
比 左/右 孩子小,则当前元素值需要下沉, 左/右 孩子元素值上升
»由于 左/右 孩子堆结构被破坏,则重新调整 左/右 孩子
1 | void max_heapify(int arr[], int start, int end) { |